CATEGORIES:
BiologyChemistryConstructionCultureEcologyEconomyElectronicsFinanceGeographyHistoryInformaticsLawMathematicsMechanicsMedicineOtherPedagogyPhilosophyPhysicsPolicyPsychologySociologySportTourism
SCIT ? Ukrainian Supercomputer Project
Super ?omputer for Information Technologies (SCIT). To solve the most important problemss in the economy, technology, and defense of Ukraine that have large computing dimensions, we need to be able to calculate extra large information arrays. Such extremely large computations are impossible without modern high-performance supercomputers.
Today in Glushkov Institute of Cybernetics NAS of Ukraine two high-performance and high effective computational cluster systems SCIT-1 and SCIT-2 are running in the mode of functional testing. They are built on the basis of modern microprocessors Intel? Xeon? and Intel? Itanium? 2 [12], [19], [20], [21].
On the basis of these supercomputer systems, a powerful joint computer resource will be built. Users from all organizations and subdivisions of the NAS of Ukraine will be able to access this resourse regardless of location.
Development Ideology.In developing a supercomputer system scientists and engineers face a great amount of questions that require running various kinds of experiments. The experiments are run to understand the performance, features and characteristics of architecture, hardware platform for computing node solution, node interconnections, networking interfaces, storage system.
To make the right decision on system architecture, an analysis of the world supercomputer tendencies have been made. As one of the major sources, the top 500 list of the largest supercomputers installations was used. The analysis made proves that the solution with cluster architecture is the right one.
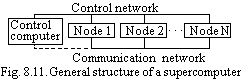 A cluster computer system ? is a group of standard hardware and software components, coupled together to solve problems (Fig. 8.11). A standard single processor or a SMP (symmetric multiprocessor system) are used as processing elements in a cluster. Standard high-performance interconnect interfaces (Ethernet, Myrinet, SCI, Infiniband, Quadrics) are used to connect processing elements in a cluster system. Development of supercomputer systems with cluster architecture is one of the most promising trends in the field of high-performance computations today. The amount of supercomputer clusters installed throughout the world is increasing rapidly and the amount of finance spent research involved is also increasing [46].
A cluster computer system ? is a group of standard hardware and software components, coupled together to solve problems (Fig. 8.11). A standard single processor or a SMP (symmetric multiprocessor system) are used as processing elements in a cluster. Standard high-performance interconnect interfaces (Ethernet, Myrinet, SCI, Infiniband, Quadrics) are used to connect processing elements in a cluster system. Development of supercomputer systems with cluster architecture is one of the most promising trends in the field of high-performance computations today. The amount of supercomputer clusters installed throughout the world is increasing rapidly and the amount of finance spent research involved is also increasing [46].

|
The worldwide trends in development of supercomputers for MPP (Massively Parallel Processing), PVP (Parallel Vector Processor) and cluster systems are shown in Fig. 8.12. Clusters are dominated in the top 500 list. For recent years, the amount of cluster systems in the list has grown whereas the amount of MPP and PVP systems is going down.
When choosing a hardware platform of computational nodes the price/performance ratio was analyzed. As LINPACK is a rather narrow test, SPECfp tests were chosen to understand the performance of the nodes on the basis of different kind of real applications. The prices for calculation were taken from Ukrainian IT market operators. The diagram obtained during this analysis is shown in Fig. 8.13.
A price/perform?ance analysis has been made with a calculation of costs of all main components of the system and its environment with a focus on the theoretical peak of 300 GFlops performance, which is about 120000 SPECfp. We have also taken into consideration performance downsize for different platform scalings on the basis of self-made tests.

|
After the analysis the Itanium 2 solution was chosen as the best scaling and best price/performance solution for floating point calculation intensive applications. But it is understood that the choice of a newest Itanium2 architecture could cause problems with available 32-bit applications porting. So, it was decided to build two systems. For SCIT-1 ? a 32xCPU system, Xeon 2.67GHz platform was chosen and for SCIT-2 ? a 64xCPU system, Itanium2 1.4GHz platform was chosen as the best one in the 64-bit floating-point performer.
Good prospects of Itanium2 architecture and also its ability to operate faster with big precision operations and big memory were also taken into account. The other valuable characte?ristics that improve the price/performance ratio of Itanium2 systems are their better values of power/per?for?mance ratio amidst other well-known processors.
We have chosen the internode communication interfaces from those with the best performance. When making experiments with one of the software packages (Gromacs), it was found out that a low latency is the most important issue for cluster scalability. From the published data and experiments performed it was seen that some of the problems which don't scale to more then 2-4 nodes on the Gigabit Ethernet scales easily to 16 nodes on low-latency interconnect interfaces.
The productivity of a ?point-to-point? channel of a cluster system is defined by the average data rate. When a message of a volume V is passed between sites, there are no other exchanges in the network. The time expended on this transfer is defined by the formula:  , where S is the throughput of the ?point-to-point? channel in an empty network or the instantaneous data rate; L is the initial time of exchange (data exchange take-off run) not depending on the volume of the message. This results in a delay termed the price of exchange which is defined by the formula:
, where S is the throughput of the ?point-to-point? channel in an empty network or the instantaneous data rate; L is the initial time of exchange (data exchange take-off run) not depending on the volume of the message. This results in a delay termed the price of exchange which is defined by the formula:  . Obviously, the higher throughput and the lower latency, the better [46].
. Obviously, the higher throughput and the lower latency, the better [46].
Understanding the importance of latency and throughput of the interface, a price/performance analysis for interfaces available in Ukraine has been made. The SCI (Scalable Coherent Interface) has appeared. The best one for 16x and 32x nodes clusters, planned to be built.
The performance data of communicational interfaces obtained in the 3rd quarter of the year 2004 for Intel Xeon platforms are shown in Figs 8.14 and 8.15. Today these Figs will look different (because of changes in the platforms and interfaces) but the price/performance leaders for latency intensive applications are SCI and QSNetII, for throughput intensive applications they are QSNetII and Infiniband. For small clusters the SCI is a preferable interface. But it also has another useful feature. An SCI system network can be built on 2D mesh topologies.

|
Such an architecture gives an ability to transfer data in two ways simultaneously. But to take advantage of this technology, the software should be written in a proper way. It is known, that performance and intelligence are the most important factors promoting the development of modern universal high-performance computers. The first factor is forced by the development of parallel architectures. The rational base of this development is universal microprocessors, connected to form cluster system architectures. The second factor becomes clear when the notion of machine intellect (MI) is used. V.M.Glushkov introduces the concept of MI which defines ?internal computer intelligence? and the term ?intellectualization? which is used to define increase of machine intellect [40].

|
During the recent years, V.M.Glushkov Institute of Cybernetics of NAS of Ukraine has carried out research aimed at the development of cluster-based knowledge-oriented architectures called intelligent solving machines (ISM). ISM implement high- and super-high-level languages (HLL and SHLL) and effective operation with large-size data and knowledge bases. They operate both with traditional computation problems (mathematical physics, modeling of complex objects and processes, etc.) and with artificial intelligence (AI) problems (knowledge engineering, pattern recognition, diagnosis, forecasting).
Large-size complex data and knowledge bases in these clusters are displayed as oriented graphs of an arbitrary complexity ? trees, semantic networks, time constrained, etc. In ISM computers it is possible to build graphs with millions of nodes and to represent various knowledge domains. It is also important that an architecture developed can be easily integrated with distributed database architectures that are developed in Glushkov institute of cybernetics of NAS of Ukraine. This data base architecture makes search processes and data processing much faster than solutions with traditional architectures do.
The intellectual part of cluster systems developed together with distributed databases is an advantage of this solution as compared with systems developed elsewhere in the world. Hardware and software of the systems are being developed. The following SCIT (supercomputer for informational technologies) supercomputers have been built in the institute (Fig. 8.16).

SCIT-1 ? 32xCPU, 16xNode cluster on the basis of Intel Xeon 2.67GHz 32-bit processors. They are oriented to operate with 64-bit and 128-bit data. The peak performance of SCIT-1 is 170 GFlops with an ability to be upgraded to 0.5-1 TFlops (right in the photo of Fig. 8.17).

SCIT-2 ? 64xCPU, 32xNode cluster on the basis of Intel Itanium2 1.4GHz 64-bit processors. They are oriented to operate with 128-bit and 256-bit data. The peak performance of SCIT-2 is 358 GFlops with an ability to be upgraded to 2.0-2.5 TFlops. With a storage system of a capacity of 1TByte and ability to be upgraded to 10-15 TBytes (left in the photo of Fig. 8.17).
Date: 2016-06-12; view: 428
| <== previous page | | | next page ==> |
| The MAJC Architecture | | | Bit performance parameters of SCIT-1 and SCIT-2 systems |