CATEGORIES:
BiologyChemistryConstructionCultureEcologyEconomyElectronicsFinanceGeographyHistoryInformaticsLawMathematicsMechanicsMedicineOtherPedagogyPhilosophyPhysicsPolicyPsychologySociologySportTourism
The MAJC Architecture
Instruction Set.The MAJC instruction set supports a load-store architecture, which loads information from memory into general-purpose registers before processing it and stores information back to memory from registers after processing it. The instruction set provides a rich set of operations to process information in the MAJC register file. Because the general-purpose registers are data-type agnostic, the instruction set must provide several variations of many instructions to process various data types. The instruction slices too are data-type agnostic. They allow an instruction to execute in any instruction slice, with the restriction that the first instruction in a VLIW packet has only one quarter of the instruction opcode space. Thus, not all operations are available to instructions for the first slice.
The instruction set provides instructions for typical RISC operations such as add and shift, as well as operations that improve the performance of both broadband-service transaction processing and Java programs. It also supports instructions for predicated and speculative execution so that the compiler can extract greater instruction-level parallelism from traditional programs [35, 61].
Often, traditional instruction set architectures cannot efficiently handle modern applications. One way that MAJC counters this inefficiency is by providing an ISA capable of handling instructions with four register specifiers. With four register specifiers, the instruction set can include instructions especially important for multimedia applications, such as muladd (fused multiplication and addition), bitext (bit extract), byteshuffle, and pickc (conditional pick). These operations, which require three source operands and one destination operand, could not be implemented in traditional architectures.
Along with greater flexibility for creating a diverse and powerful instruction set, MAJC potentially provides many more general-purpose registers than a typical architecture. As previously described, up to 416 data-type-agnostic general-purpose registers let complex algorithms execute completely from the register file. This eliminates the need for additional memory instructions to fill and spill variables into and out of the register file, as would be necessary in architectures that do not support many registers. Thus, the expansive MAJC register file results in higher application performance.
In accordance with the goal of exploiting instruction-level parallelism, the MAJC instruction set provides instructions to aid the compilers predication and speculation techniques. The pickc (conditional pick), movc (conditional move), and stcd (conditional store double-word) instructions, for instance, support speculatively executing code, thus extracting greater instruction-level parallelism. To fully utilize the instruction slices in an implementation, the compiler can hoist loads by executing them speculatively with nonfaulting load instructions.
Beyond instruction-level parallelism, the MAJC instruction set also includes instructions to enhance the performance of Java applications. The blkzero (block zero) instruction writes zero to a region of memory. Typically, Java virtual machines initialize large memory blocks. To accomplish this, most microprocessors use stores, which may unnecessarily transfer data from main memory into a cache. Blkzero optimizes this process by removing the unnecessary memory accesses. Another instruction that enhances Java application performance is bndchk (bound check). This instruction checks three conditions necessary for an array access in Java and causes a trap if any of them is true. This single instruction achieves an operation that requires numerous instructions, including calculations, comparisons, and branches, in most other instruction sets.
Moreover, MAJC includes stiw (store instruction word). This instruction is targeted at the self-modifying code feature of many Java virtual machines, which replaces certain instructions with other instructions during runtime for performance enhancement. Unlike normal store instructions, stiw snoops the VLIW packet stream. Without stiw, normal stores would be forced to snoop the VLIW packet stream to appropriately handle self-modifying code. Stiw makes this overhead unnecessary.
Beyond Java-enhancing instructions, the MAJC instruction set provides a set of powerful instructions for broadband-service transaction processing. These instructions include various single- and double-precision floating-point arithmetic operations such as maximum, minimum, absolute value, negate value, and reciprocal square root. These operations form a math library that facilitates graphics and multimedia applications. Individually, the maximum and minimum operations are very useful for voice recognition applications, and the reciprocal square root operation is very useful for vector normalization in graphics. MAJC also provides four-operand muladd and mulsub instructions. The floating-point versions of these instructions support graphics transformations, and the integer versions support graphics lighting computations. Another powerful instruction is the floating-point clip operation, which determines the relationship between two single-precision floating-point numbers to support graphics window clipping.
For 8-bit, 16-bit, and, if the architectural width is 64, 32-bit operations that would not fully utilize the data path on their own, the MAJCinstruction set provides SIMD instructions important in media processing. These include addition, subtraction, mean value, power, shift, compare, move, fused multiplication and addition, dot-product-with-addition, and dot-product-with-subtraction calculations. The powerp (parallel power) instruction works well in graphics lighting, and the dotaddp and dotsubp instructions support 16-bit integer fast Fourier transforms and inverse discrete cosine transforms for MPEG-2 applications. The meanp instruction performs motion compensation calculations in MPEG-2 and DVD applications.
Moreover, variations of instructions with the ADD prefix perform parallel operations (SIMD), use various rounding methods, and execute with saturation. There are combinations of these variations such as addhs, which adds two 16-bit halfwords in parallel with saturation.
Through the instruction set enhancements, multimedia and graphics applications can achieve significantly better performance on a MAJC microprocessor than on traditional general-purpose microprocessors.
Support for Threads.The popularity of Java, which provides native support for multithreaded programs, has increased the availability of such programs. The use of multiprocessor systems is growing rapidly to meet the Internet?s increasing data-processing demands. Broadband services require even greater processing capability. Typically, these services are multithreaded or contain multiple processes. To address these types of applications, MAJC supports thread-and process-level parallelism.
MAJC supports processor units containing multiple microthreads. This scheme supports vertical multithreading by having multiple execution streams share the resources in a processor unit on a cycle-by-cycle basis. Vertical multithreading allows more efficient use of a processor unit's resources by allowing another thread to use resources that a stalled thread is not using. In turn, processing throughput increases when there are multiple threads or processes to execute. With an increasing number of transactions on the Internet, each fairly independent of other transactions and capable of being processed with separate threads, throughput becomes increasingly important.
Additionally, MAJC has processor clusters that contain multiple processor units. These processor clusters support CMPs, which have drawn much attention from microprocessor architects in industry and academia. As process technology improves as predicted by Moore's law, CMP technology is one way to use the huge number of transistors available in next-generation microprocessors to process more data faster. In other words, it is a method of increasing throughput.
From a software perspective, vertical multithreading and CMPs are ideal platforms for processing multiprogrammed of multithreaded workloads. Each microthread can process an independent subset of the workload, an effective throughput-enhancing technique. In addition, a processor cluster can reduce the latency of a multithreaded program by running threads on separate processor units concurrently.
Single-threaded programs typically execute in a single microthread. Compilers have difficulty parallelizing most single-threaded programs (except for a restricted class of numerical applications) to generate multiple threads. So, unless a programmer manually threads a program, it won't benefit from the availability of multiple microthreads. Speculative multithreading addresses this problem. A single-threaded program is speculatively threaded at loops or function calls even though dependencies may exist between the threads. Many proposed CMP systems have additional hardware to support this speculation efficiently. There may be data dependencies between threads both in program memory and in register values. Register values can be shared through memory and explicit synchronization to model the data's producer-consumer relationship. However, synchronization can be expensive in large CMP systems. Thus, most proposed CMPs have a dedicated bus to pass these register values correctly between threads.
MAJC speeds single-threaded-program execution by using speculative multithreading on multiple microthreads. The architecture provides virtual channels between different microthreads in a processor cluster to communicate shared register values with producer-consumer synchronization. A speculative thread may have a register read-after-write dependency on a nonspeculative or less speculative thread executing in a different micro thread. Code in the nonspeculative or less speculative thread forwards the register value to the speculative thread through a virtual channel. This allows speculative threads to maintain the sequential semantics of the original single-threaded program while still executing somewhat in parallel. However, an implementation or the compiler still must perform memory disambiguation to maintain memory data dependencies between the non-speculative and speculative threads. The virtual channels are accessible through load and store operations and do not have direct access to the MAJC architectural registers.
The architecture also provides fast interrupts between microthreads in a processor cluster so that threads running on different microthreads can quickly notify each other of pertinent events. This fast notification enables speculative threads to be generated and rolled back quickly, reducing the overhead of thread speculation. In addition to their uses for speculative multithreading, virtual channels and fast interrupts benefit multithreaded programs that require producer-consumer data sharing and fast communication.
Virtual channels allow easy maintenance of register dependencies between a nonspeculative thread and speculative threads. A MAJC implementation or compiler still must maintain the correct memory data dependencies between a nonspeculative thread and speculative threads as if they had executed in sequential program order. For typical C or C++ programs, the implementation may have to provide fairly complex hardware to detect and maintain data dependencies between memory operations from each thread. Or the compiler may have to insert significant additional code to check for memory data dependencies between threads if it cannot disambiguate memory operations. Additionally, store operations from a speculative thread must not be committed until the thread becomes nonspeculative. Thus, the implementation must buffer a speculative thread's store operations, or the compiler must version the variables that the store operations update.
Java programs have properties that reduce the overhead of software-based checks for memory data dependencies and versioning of variable updates from speculative threads. These properties allow speculative multithreading of single-threaded Java programs on the MAJC architecture, without complex hardware and large software overhead, using a technique called space-time computing (STC).
STC takes advantage of Java's byte-code properties, which allow runtime software to differentiate between memory operations to the stack and to the heap. STC ensures that variables shared between a nonspeculative thread and speculative threads are shared only through the heap. It achieves this by moving variables from the stack to the heap, if necessary, when speculatively threading at loop boundaries. Variables ? except for that containing the predicted return value ? are never shared through the stack when STC speculatively threads across method boundaries. With STC, the checks for memory data dependencies between threads are necessary only on memory operations to the heap. The number of memory operations to the stack is usually significantly larger than the number of operations to the heap. Very little code is added to the nonspeculative thread for memory-dependency checking. STC also takes advantage of the Java exception and monitor synchronization model to make the speculative thread as efficient as the nonspeculative thread, even with memory-dependency checking.
The Java stacks state is known at the launch of a speculative thread. The speculative thread uses its own stack for its execution and copies data from the launching threads stack one frame at a time as needed. Variables in the heap that are updated by a speculative thread are versioned with code in the thread until it becomes non-speculative. The nonspeculative thread operates in current time and in current memory space. The speculative threads operate in their own separate memory space and future time. When a speculative thread becomes nonspeculative, its space and time dimensions collapse into the current space and time dimensions ? hence the term space-time computing.
A system with two threads ? a nonspeculative head thread and a speculative thread ? illustrates the use of STC for speculative multithreading of a single-threaded Java program. We use this system here to explain the STC operation concisely; it can easily be extended to support a greater number of speculative threads. Also, we have omitted a variety of optimizations for clarity.
During a load to a heap variable, the speculative thread updates the status information associated with the variable before loading to its version of the variable. The variable's status information can be kept with the object or array that contains the variable and can be shared with other variables. Also, during a store to a heap variable, the speculative thread updates the variable's status information before determining if it has versioned the variable. If the variable has not been versioned, the speculative thread creates a version for itself. It then stores to its version of the variable. It also maintains a versioned-objects list.
During a store to a heap variable, the head thread updates all versions of the variable. This allows loads from the variable in the speculative thread to receive the forwarded value from the head thread if the loads were not performed before the store in the head thread. The head thread also checks the variables status information to determine whether the speculative thread has violated a memory dependency on the variable. If so, the head thread causes the speculative thread to roll back so that the memory dependencies of the program are maintained. Then, the speculative thread uses the versioned-objects list to destroy its versioned variables.
As mentioned earlier, MAJC assumes the release consistency memory model. The speculative thread requires that the store to a variable's status information be ordered with respect to the load to that variable. The head thread also requires that stores total a variables versions be ordered with respect to the load from the status information. Release consistency does not order loads and stores to different memory locations, so architectures typically need memory barrier instructions to provide the ordering. Memory barrier instructions can have a significant performance penalty because they order more than the required loads and stores. In contrast, MAJC orders only the necessary loads and stores, using special load and store flavors.
The widespread adoption of the Java platform and the need to support broadband-enabled applications gave us a great opportunity to rethink the design of microprocessors and computer systems. MAJC represents attempts to take a broad new look at parallelism. It uses microarchitecture techniques and compiler optimizations to exploit instruction-level parallelism. MAJC-based systems will deliver even more application performance by exploiting thread-level parallelism and leveraging the characteristics of high-level languages such as Java.
A well-constructed architecture should form the foundation of state-of-the-art implementations that can be produced by design teams of less than 100 people. Otherwise, implementations tend to become too complex, resulting in
? more staff-years needed for physical implementations,
? more staff-years needed for developing and optimizing compilers and system software,
? more power needed to achieve high clock frequencies (due to expensive and exotic circuits), and
? management difficulties in maintaining effective communication with a large team (potentially leading to staff retention problems).
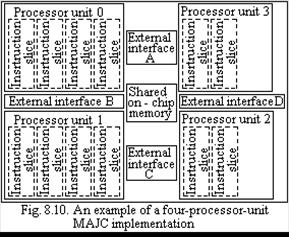 A MAJC Implementation Example.Fig. 8.10 shows a MAJC implementation example. In this configuration, the processor cluster consists of four processor units. PUs 0 and 1 are four-issue units, each containing, say, 96 global general-purpose registers and 32 private general-purpose regis?ters per instruction slice plus 2 and 3 are two-issue units, each containing, say, 32 global general-purpose registers and no private general-purpose regis?ters. Therefore, this processor cluster contains 512 general-purpose registers.
A MAJC Implementation Example.Fig. 8.10 shows a MAJC implementation example. In this configuration, the processor cluster consists of four processor units. PUs 0 and 1 are four-issue units, each containing, say, 96 global general-purpose registers and 32 private general-purpose regis?ters per instruction slice plus 2 and 3 are two-issue units, each containing, say, 32 global general-purpose registers and no private general-purpose regis?ters. Therefore, this processor cluster contains 512 general-purpose registers.
Date: 2016-06-12; view: 468
| <== previous page | | | next page ==> |
| Synthesis of Parallelism and Scalability | | | SCIT ? Ukrainian Supercomputer Project |