CATEGORIES:
BiologyChemistryConstructionCultureEcologyEconomyElectronicsFinanceGeographyHistoryInformaticsLawMathematicsMechanicsMedicineOtherPedagogyPhilosophyPhysicsPolicyPsychologySociologySportTourism
Deep Pipelining (10 stages)
The cycle time and the core pipeline are balanced and optimized for the sequential execution in integer scalar codes, by minimizing the latency of the most frequent operations, thus reducing dead time in the overall computation. The high frequency (800 MHz) and careful pipelining enable independent operations to flow through this pipeline at high throughput, thus also optimizing vector numeric and multimedia computation. The cycle time accommodates the following key critical paths:
? single-cycle ALU, globally bypassed across four ALUs and two loads;
? two cycles of latency for load data returned from a dual-ported level-1 (LI) cache of 16 Kbytes; and
? scoreboard and dependency control to stall the machine on an unresolved register dependency.
The feature set complies with the high-frequency target and the degree of pipelining ? aggressive branch prediction, and three levels of on-package cache. The pipeline design employs robust, scalable circuit design techniques. We consciously attempted to manage interconnect lengths and pipeline away secondary paths.
Fig. 7.7 illustrates the 10-stage core pipeline. The bold line in the middle of the core pipeline indicates a point of decoupling in the pipeline. The pipeline accommodates the decoupling buffer in the ROT (instruction rotation) stage, dedicated register-remapping hardware in the REN (register rename) stage, and pipelined access of the large register file across the WLD (word line decode) and REG (register read) stages. The DET (exception detection) stage accommodates delayed branch execution as well as memory exception management and speculation support.

Dynamic Hardware for Runtime Optimization.While the processor relies on the compiler to optimize the code schedule based upon the deterministic latencies, the processor provides special support to dynamically optimize for several compilation time indeterminacies.
These dynamic features ensure that the compiled code flows through the pipeline at high throughput. To tolerate additional latency on data cache misses, the data caches are non-blocking, a register Scoreboard enforces dependencies, and the machine stalls only on encountering the use of unavailable data.
We focused on reducing sensitivity to branch and fetch latency. The machine employs hardware and software techniques beyond those used in conventional processors and provides aggressive instruction prefetch and advanced branch prediction through a hierarchy of branch prediction structures. A decoupling buffer allows the front end to speculatively fetch ahead, further hiding instruction cache latency and branch prediction latency.
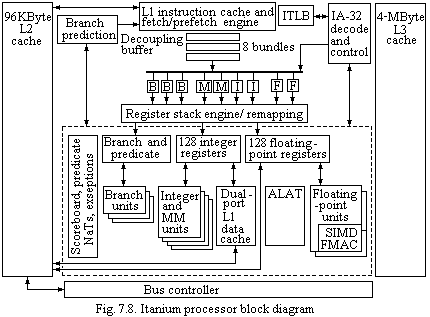 Fig. 7.8 provides the block diagram of the Itanium processor, Fig. 7.9 provides a plot of the silicon database. A few top-level metal layers have been stripped off to create a suitable view.
Fig. 7.8 provides the block diagram of the Itanium processor, Fig. 7.9 provides a plot of the silicon database. A few top-level metal layers have been stripped off to create a suitable view.
Details of the Core Pipeline.The following describes details of the core processor microarchitecture. Given the high execution rate of the processor (six  instructions per clock), an aggressive front end is needed to keep the machine effectively fed, especially in the presence of disruptions due to branches and cache misses. The machine's front end is decoupled from the back end.
instructions per clock), an aggressive front end is needed to keep the machine effectively fed, especially in the presence of disruptions due to branches and cache misses. The machine's front end is decoupled from the back end.
 Acting in conjunction with sophisticated branch prediction and correction hardware, the machine speculatively fetches instructions from a moderate-size, pipelined instruction cache into a decoupling buffer. A hierarchy of branch predictors, aided by branch hints, provides up to four progressively improving instruction pointer resteers. A software-initiated prefetch probe for future misses in the instruction cache and then prefetches such target code from the level-2 (L2) cache into a streaming buffer and eventually into the instruction cache. Fig. 7.10 illustrates the front-end microarchitecture.
Acting in conjunction with sophisticated branch prediction and correction hardware, the machine speculatively fetches instructions from a moderate-size, pipelined instruction cache into a decoupling buffer. A hierarchy of branch predictors, aided by branch hints, provides up to four progressively improving instruction pointer resteers. A software-initiated prefetch probe for future misses in the instruction cache and then prefetches such target code from the level-2 (L2) cache into a streaming buffer and eventually into the instruction cache. Fig. 7.10 illustrates the front-end microarchitecture.
Speculative fetches. The 16-Kbyte, four-way set-associative instruction cache is fully pipelined and can deliver 32 bytes of code (two instruction bundles or six instructions) every clock. The cache is supported by a single-cycle, 64-entry instruction translation look-aside buffer (TLB) that is fully associative and backed up by an on-chip hardware page walker.
The fetched code is fed into a decoupling buffer that can hold eight bundles of code. As a result of this buffer, the machine's front-end can continue to fetch instructions into the buffer even when the back-end stalls. Conversely, the buffer can continue to feed the back-end even when fetch bubbles due to branches disrupt the front-end or instruction cache misses.
Hierarchy of branch predictors. The processor employs a hierarchy of branch prediction structures to deliver high-accuracy and low-penalty predictions across a wide spectrum of workloads. Note that if a branch misprediction led to a full pipeline flush, there would be nine cycles of pipeline bubbles before the pipeline is full again. This would mean a heavy performance loss. Hence, significant emphasis is placed on boosting the overall branch prediction rate as well as reducing the branch prediction and correction latency.
The branch prediction hardware is assisted by branch hint directives provided by the compiler (in the form of explicit branch predict, or BRP, instructions as well as hint specifier on branch instructions). The directives provide branch target addresses, static hints on branch direction, as well as indications on when to use dynamic prediction. These directives are programmed into the branch prediction structures and used in conjunction with dynamic prediction schemes. The machine provides up to four progressive predictions and corrections to the fetch pointer, greatly reducing the likelihood of a full-pipeline flush due to a mispredicted branch.
? Resteer 1: Single-cycle predictor. A special set of four branch prediction registers (called target address registers, or TARs) provides single-cycle turnaround on certain branches (for example, loop branches in numeric code), operating under tight compiler control. The compiler programs these registers using BRP hints, distinguishing these hints with a special "importance" bit designator and indicating that these directives must get allocated into this small structure. When the instruction pointer of the candidate branch hits in these registers, the branch is predicted taken, and these registers provide the target address for the resteer. On such taken branches no bubbles appear in the execution schedule due to branching.
? Resteer 2: Adaptive multiway and return predictors. For scalar codes, the processor employs a dynamic, adaptive, two-level prediction scheme to achieve well over 90% prediction rates on.
The branch prediction table (BPT) contains 512 entries (128 sets × 4 ways). Each entry, selected by the branch address, tracks the four most recent occurrences of that branch. This 4-bit value then indexes into one of 128 pattern tables (one per set). The 16 entries in each pattern table use a 2-bit, saturating, up-down counter to predict branch direction.
The branch prediction table structure is additionally enhanced for multiway branches with a 64-entry, multiway branch prediction table (MBPT) that employs a similar algorithm but keeps three history registers per bundle entry. A find-first-taken selection provides the first taken branch indication for the multiway branch bundle. Multiway branches are expected to be common in EPIC code, where multiple basic blocks are expected to collapse after use of speculation and predication.
Target addresses for this branch resteer are provided by a 64-entry target address cache (TAC). This structure is updated by branch hints (using BRP and move-BR hint instructions) and also managed dynamically. Having the compiler program the structure with the upcoming footprint of the program is an advantage and enables a small, 64-entry structure to be effective even on large commercial workloads, saving die area and implementation complexity. The BPT and MBPT cause a front-end resteer only if the target address for the resteer is present in the target address cache. In the case of misses in the BPT and MBPT, a hit in the target address cache also provides a branch direction prediction of taken.
A return stack buffer (RSB) provides predictions for return instructions. This buffer contains eight entries and stores return addresses along with corresponding register stack frame information.
? Resteers 3 and 4: Branch address calculation and correction. Once branch instruction opcodes are available (ROT stage), it's possible to apply a correction to predictions made earlier. The BAC1 stage applies a correction for the exit condition on modulo-scheduled loops through a special "perfect-loop-exit-predictor" structure that keeps track of the loop count extracted during the loop initialization code. Thus, loop exits should never see a branch misprediction in the back end. Additionally, in case of misses in the earlier prediction structures, BACl extracts static prediction information and addresses from branch instructions in the rightmost slot of a bundle and uses these to provide a correction. Since most templates will place a branch in the rightmost slot, BACl should handle most branches. BAC2 applies a more general correction for branches located in any slot.
Software-initiated prefetch. Another key element of the front-end is its software-initiated instruction prefetch. Prefetch is triggered by prefetch hints (encoded in the BRP instructions as well as in actual branch instructions) as they pass through the ROT stage. Instructions get prefetched from the L2 cache into an instruction-streaming buffer (ISB) containing eight 32-byte entries. Support exists to prefetch either a short burst of 64 bytes of code.
Software-initiated prefetch. Another key element of the front end is its software-initiated instruction prefetch. Prefetch is triggered by prefetch hints (encoded in the BRP instructions as well as in actual branch instructions) as they pass through the ROT stage. Instructions get prefetched from the L2 cache into an instruction-streaming buffer (ISB) containing eight 32-byte entries. Support exists to prefetch either a short burst of 64 bytes of code (typically, a basic block residing in up to four bundles) or a long sequential instruction stream. Short burst prefetch is initiated by a BRP instruction hoisted well above the actual branch. For longer code streams, the sequential streaming ("many") hint from the branch instruction triggers a continuous stream of additional prefetch requests until a taken branch is encountered. The instruction cache filters prefetch requests. The cache tags and the TLB have been enhanced with an additional port to check whether an address will lead to a miss. Such requests are sent to the L2 cache.
The compiler can improve overall fetch performance by aggressive issue and hoisting of BRP instructions, and by issuing sequential prefetch hints on the branch instruction when branching to long sequential codes. To fully hide the latency of returns from the L2 cache, BRP instructions that initiate prefetch should be hoisted 12 fetch cycles ahead of the branch. Hoisting by five cycles breaks even with no prefetch at all. Every hoisted cycle above five cycles has the potential of shaving one fetch bubble. Although this kind of hoisting of BRP instructions is a tall order, it does provide a mechanism for the compiler to eliminate instruction fetch bubbles.
Date: 2016-06-12; view: 393
| <== previous page | | | next page ==> |
| The Itanium Processor Microarchitecture | | | Efficient Instruction and Operand Delivery |