CATEGORIES:
BiologyChemistryConstructionCultureEcologyEconomyElectronicsFinanceGeographyHistoryInformaticsLawMathematicsMechanicsMedicineOtherPedagogyPhilosophyPhysicsPolicyPsychologySociologySportTourism
The SPARC Computers Family
 HyperSPARC II Processor Chips Set.All these design differences are the subject of fierce technical arguments, and the literature is unusually full of advocacy documents that argue strongly for one or the other approach, often backed up by benchmarks of the usual questionable nature (See Fig.5.6).
HyperSPARC II Processor Chips Set.All these design differences are the subject of fierce technical arguments, and the literature is unusually full of advocacy documents that argue strongly for one or the other approach, often backed up by benchmarks of the usual questionable nature (See Fig.5.6).
Which of the two architectures really is better? This isn't an easy question to answer. For one thing, it is hard to separate the architecture from its implementations. Current implementations of the MIPS seem to be somewhat more efficient that those of the SPARC ? the CYPRESS, for example, is still burdened by a three-clock store. However, this does not seem to be a necessary consequence of the architectural differences.
Just as a programmer can make a theoretically less efficient algorithm run faster by clever coding, a hardware designer can often overcome architectural difficulties with clever implementation. A reasonable conclusion is that the two approaches are roughly equivalent in performance. Both architectures clearly demonstrate the viability of the fundamental RISC notion that simplifying the instruction set design can lead to significantly improved performance.
UltraSPARC II System Pipeline.The UltraSPARC II System contains the pipeline with 9 stages. Some of these stages are different for instructions with integer numbers and for instructions with floating point numbers (Fig. 5.7). At the first stage, instructions are fetched from the instruction cache (if possible).

At the favorable circumstances (absence of cache misses, incorrect branching prognoses, complex instructions, presence of the correct instruction mixtures, etc.) the machine may continue fetching and start 4 instructions at a cycle. At the decoding stage, before copying instructions into the queue, additional bits are added to each of them. These bits accelerate the successive processing (e.g., at once sending the instruction into the appropriate functional unit). The grouping stage corresponds to the grouping scheme that was considered earlier. At this stage, the decoded instructions are united to groups. There are 4 instructions in each group. All the instruction of each group should be selected in such way that all of them may be executed simultaneously.
From the moment of this stage, the further operations with integer numbers and numbers with floating point are disjointed. At stage 4, most instructions in the unit of integer numbers are executed really during one cycle. But the instructions S??R? and LOAD require additional processing at the caching stage. At stages N1 and N2, no actions are performed for instructions, but these stages are necessary for two pipelines synchronization. If each instruction with integer numbers is completed some seconds later, this is not large loss, but the pipeline works uniformly. The unit for processing numbers with floating point contains separate 4 stages. The first one is necessary for accessing to registers with floating point. The next three ones are necessary for the instruction executing. All the instructions with floating point are executed during three cycles, not counting division (this operation require 12 cycles) and square-rooting (here 22 cycles are necessary), that?s why the long sequence of another instructions doesn?t decrease the tempo of the pipeline work. Stage N3 is common for both units and used for resolution of exceptional situations, e.g., division by zero. At the last stage, the results are written back into the registers.
OpenSPARC Tl Processor.These megacells include various register files, translation lookaside buffers (TLBs), content-addressable memory (CAM), Level 2 cache (L2-cache), and arrays (Fig. 5.8).
? 6 Kbyte primary instruction cache memory per core
- 6 Kbyte primary data cache memory per core
- 64-entry fully associative instruction TLB per core
- 64-entry fully associative data TLB per core
-
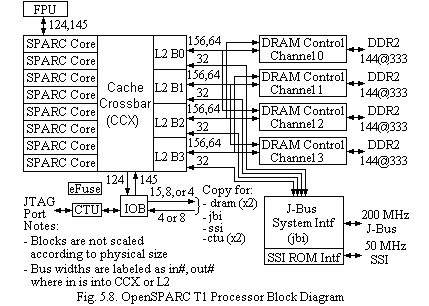 3 Mbyte unified L2-cache
3 Mbyte unified L2-cache - Four DRAM controllers interfacing to DDR2 SDRAM
OpenSPARC Tl Processor Components.Each SPARC core has hardware support for four threads. This support consists of a full register file (with eight register windows) per thread, with most of the address space identifiers (ASI), ancillary state registers (ASR), and privileged registers replicated per thread. The four threads share the instruction and data caches and TLBs. Each instruction cache is 16 Kbytes with a 32-byte line size. The data caches are write through, 8 Kbytes, and have a 16-byte line size. An autodump feature is included with the TLBs to enable the multiple threads to update the TLB without locking. A single floating-point unit (FPU) is shared by all eight SPARC cores. The shared floating-point unit is sufficient for most commercial applications in which typically less than 1% of the instructions are floating-point operations.
The L2-cache is banked four ways, with the bank selection based on physical address bits 7:6. The cache is 3 Mbyte, 12-way set-associative with pseudo-least recently used (LRU) replacement (replacement is based on a used bit scheme). The line size is 64 bytes. Unloaded access time is 23 cycles for an L1 data cache miss and 22 cycles for an L1 instruction cache miss.
The OpenSPARC Tl processor's DRAM controller is banked four ways (a two-bank option is available for cost-constrained minimal memory configurations), with each L2 bank interacting with exactly one DRAM controller bank. The DRAM controller is interleaved based on physical address bits 7:6, so each DRAM controller bank must have identical dual in-line memory modules (DIMM) installed and enabled.
The OpenSPARC Tl processor uses DDR2 DIMMs and can support one or two ranks of stacked or unstacked DIMMs. Each DRAM bank/port is two-DIMMs wide (128 bit + 16 bit ECC). All installed DIMMs must be identical, and the same number of DIMMs (that is, ranks) must be installed on each DRAM controller port. The DRAM controller frequency is an exact ratio of the core frequency, where the core frequency must be at least three times the DRAM controller frequency. The double data rate (DDR) data buses transfer data at twice the frequency of the DRAM controller frequency.
The I/O bridge (IOB) performs an address decode on I/O-addressable transactions and directs them to the appropriate internal block or to the appropriate external interface (J-Bus or serial system interface). In addition, the JBI maintains the register status for external interrupts.
The J-Bus interface IOB is the interconnect between the OpenSPARC Tl processor and the I/O subsystem. J-Bus is a 200 MHz, 128-bit wide, multiplexed address or data bus, used predominantly for direct memory access (DMA) traffic, plus the programmable input/output (PIO) traffic to control it. The J-Bus interface is the block that interfaces to J-Bus, receiving and responding to DMA requests, routing them to the appropriate L2 banks, and also issuing PIO transactions on behalf of the processor threads and forwarding responses back. The OpenSPARC Tl processor has a 50 Mbyte/sec serial system interface (SSI) that connects to an external application specific integrated circuit (ASIC), which in turn interfaces to the boot read-only memory (ROM). In addition, the SSI supports PIO accesses across the SSI, thus supporting optional control status registers (CSR) or other interfaces within the ASIC.
The electronic fuse (e-Fuse) block contains configuration information that is electronically burned in as part of manufacturing, including part serial number and core available information.
OpenSPARC Tl Memory System.The OpenSPARC Tl chip supports four memory channels. For low-cost system configurations, a two-channel mode can be selected by means of software-programmable control registers. Each channel supports DDR2 JEDEC standard DIMMs. The types of DRAM components supported are 256 Mbit, 512 Mbit, 1 Gbit and 2 Gbit. The maximum speed of the DIMMs supported is 200 MHz clock (400 MHz data rate). The controller works on single-ended data query system (DQS) only and has the capability to detect any double-nibble error or correct any single-nibble error contained in one 144-bit chunk. The controller always assumes that additive latency (AL) is zero. The maximum physical address space supported by the controller is 128 Gbytes (37 bits of physical address).
The OpenSPARC Tl chip contains an on-die termination (ODT) feature that is selectable in the DRAM Read Enable Clock Invert, ODT enable mask, and VREF control register. The purpose of this feature is to improve read timing by reducing the intersymbol interference (ISI) effects on the network. This feature terminates the data query (DQ) and DQS pins with the equivalent of 150 ohms (Q) to VDD18/2 under all conditions except when the DQ and DQS pins are enabled during write transactions.
OpenSPARC Tl Clock Architecture.Three synchronous clock domains are on the OpenSPARC Tl processor - CMP (for SPARC and caches), J-Bus (for IOB and JBI), and DRAM (for the DRAM controller and external DIMMs). All of these are sourced from the same phase-locked loop (PLL). Synchronization pulses are generated to control transmission of signals and data across clock domain boundaries. The clock and test unit (CTU) is responsible for resetting the PLL and counting the lock period. Once sufficient time has passed to enable the PLL to have locked, the clock control logic is responsible for enabling distribution below the cluster levels by turning on cluster enables.
The processor has two flavors of reset - power-on reset (POR) and warm reset. POR is defined as the reset event arising from turning power on to the chip and is triggered by assertion of power-on reset. Warm reset encompasses all resets when the chip has been in operation prior to the event triggering the reset. The CTU contains the JTAG block, which enables access to the shadow scan chains. The unit also has a control register (CREG) interface that enables the JTAG to issue reads of any I/O addressable register, some ASI locations, and any memory location while the processor is in operation. The OpenSPARC Tl processor contains an IEEE 1149.1-compliant test access port (TAP) controller with the standard five-pin JTAG interface. In addition to the standard IEEE 1149.1 instructions, roughly 20 private instructions provide access to the processor's design for testability (DFT) features. The OpenSPARC Tl processor includes many special features for reliability, availability, serviceability (RAS), and related areas.
The processor supports chip-kill error correction for main memory. Any error contained within a single-aligned memory nibble (4 bits) can be corrected, and any error that is contained within any two nibbles can be detected as uncorrectable. Each OpenSPARC Tl DRAM controller has a background hardware error scanner and scrubber to reduce the incidence of multi-nibble errors. If a correctable error is found, the error is logged, corrected, and written back (scrubbed in hardware) to memory. The L2-cache also has a background scanner and scrubber.
The processor has an on-chip thermal diode connected to I/O pins, enabling system hardware to obtain a rough measure of the chip temperature. If an over temperature condition is detected, the CPU can be shut down, or CPU utilization can be throttled to reduce power consumption.
Each OpenSPARC Tl SPARC thread has two performance counters that count instructions plus occurrences of one other event. The possible other events include cache misses of various types, TLB traps, and store buffer full occurrences. Counts can be qualified to count events in User mode, Supervisor mode, or both. Two counters in each DRAM controller can be used to count transactions and latency for different operations, which can be used to compute average latency. The J-Bus unit also has two performance counters. Like the DRAM counters, these counters can be used to count events and latencies and to compute average latency. In addition to the usual scan chains, the processor has shadow scan capability. This enables scan extraction of some of the processor state while execution continues. Shadow scan is provided on a per thread basis for the SPARC cores. The rest of the chip has a separate shadow scan chain. The OpenSPARC Tl processor contains both a dedicated debug port (Debug Port A) and a J-Bus debug port (Debug Port B). The debug port target bandwidth for logic analysis is 40 bits at J-Bus frequency, which is matched to the width of a single internal debug port selection. This bandwidth is sufficient for an address header every J-Bus cycle.
The signals are arranged in functional groups according to their associated interface. The processor primarily consists of DDR2 400 SDRAM signals and J-Bus signals. Fig. 5.9 shows the main interfaces and the number of signals.

UltraSPARC T1.The T1 is a derivative of the UltraSPARC T1 series of microprocessors. It is Sun's first multicore processor with multithreading. The processor is available with four, six or eight CPU cores, each core able to handle four threads concurrently. Thus the processor is capable of processing up to 32 threads concurrently. Similar to how high-end Sun SMP systems work, the UltraSPARC T1 can be partitioned. Thus, several cores can be partitioned for running a single or group of processes and/or threads, whilst the other cores deal with the rest of the processes on the system. The UltraSPARC T1 was designed from scratch as a multi-threaded, special-purpose processor, and thus introduces a whole new architecture for obtaining high performance. Rather than try to make each core as intelligent and optimized as they can, Sun's goal was to run as many concurrent threads as possible, and maximize utilization of each core's pipeline.
The T1's cores are less complex than those of current high end processors in order to allow 8 cores to fit on the same die. The cores do not feature out-of-order execution, or a sizable amount of cache. Single-thread processors depend heavily on large caches for their performance because cache misses result in a wait while the data is fetched from main memory. By making the cache larger the probability of a cache miss is reduced, but the impact of a miss is still the same. The T1 cores largely side-step the issue of cache misses by multithreading. When a cache miss occurs, the core switches to another thread (assuming one is available) while the data is fetched into cache in the background. This may make each thread slower, but the overall throughput (and utilization) of each core is much higher. It also means that much of the impact of cache misses is removed, and the T1 can maintain high throughput with a smaller amount of cache. The cache no longer needs to be large enough to hold all or most of the "working set", just the recent cache misses of each thread. The microprocessor is unique in its abilities, and as such is targeted at a particular market. Rather than being used for high-end number-crunching and ultra-high performance applications, the chip will be targeted at network-facing high-demand servers, which often utilize a large number of separate threads. One of the limitations of the UltraSPARC T1 design is that a single floating point unit is shared between all 8 cores, making the T1 unsuitable for applications performing a lot of floating point mathematics. However, since the processor's intended market does not typically make much use of floating-point operations, Sun does not expect this to be a problem.
Date: 2016-06-12; view: 364
| <== previous page | | | next page ==> |
| Floating-Point on the SPARC | | | The Power Architecture |