CATEGORIES:
BiologyChemistryConstructionCultureEcologyEconomyElectronicsFinanceGeographyHistoryInformaticsLawMathematicsMechanicsMedicineOtherPedagogyPhilosophyPhysicsPolicyPsychologySociologySportTourism
SPARC Addressing Modes and Instruction Set
As in the case of the MIPS, the SPARC has a small number of addressing modes, although it is slightly more flexible than the MIPS. Not only is the number of addressing modes limited, but also their use is restricted to the various types of load and store instructions described in the next section. This way of doing things is consistent with RISC constraints, and the SPARC addressing modes are faithful to the RISC philosophy. First of all, as with all RISC machines, there is no direct addressing of data. It is simply impossible to fit a 32-bit address into one of these instruction formats. The SPARC does include an addressing form that allows a programmer to access the lower 213 bytes of memory, but this is of limited use.
The instruction formats of the load and store instructions come in two versions. In the first form, giving a register and a 13-bit offset specifies the source operand address. In the second form, two registers whose values are added to form the address specify the source address.
The first of these modes allows a 13-bit immediate value to be added to a register to form an address. This can be used to implement what we have called based addressing. For static data, a register can point to the base address of the data, using the 13-bit offset to address some item within the area. For data allocated on the stack, the register might be used as a frame pointer, with the 13-bit offset used to select an item within the stack frame. Finally, for dynamic data, we might use the register as a pointer to a dynamically allocated record, the offset once again being used to locate a particular field. The second of these formats, where two registers are added together, also maps nicely into some of the addressing modes. The based addressing plus index mode requires two registers, one for the base address of the array and the other for the scaled index value. Indexed addressing of static data could be accomplished by using one register to point to the start of the static array and the other register to hold the scaled index.
From this discussion we can see that many of the addressing modes are available even with the limited addressing hardware of the SPARC. There are, however, some situations where the SPARC lacks a required addressing mode. For example, consider the case of an array allocated within a stack frame. To access an element of such an array, one needs two registers, one to serve as a frame pointer and one to hold the index, as well as an immediate value for the offset of the starting location of the array. But the SPARC addressing modes allow the first source register to be added either to another register or to the 13-bit immediate, not both. So this type of addressing would require an extra instruction on the SPARC.
Each of the IU load instructions has a variant whose assembly language syntax is indicated by appending an A and whose effect is to enable an alternate address space. When one of these special load and store instructions is issued, an 8-bit field within the instruction holds an alternate address space identifier (ASI). In the resulting memory access, this 8-bit ASI is appended to the front of the standard 32 bits. The 40-bit extended address is then presented to the "outside" world.
The Short Offset.The SPARC offset is painfully short?only 13 bits compared with the 16-bit offsets of the MIPS. This is a noticeable limitation for some uses. For instance, stack frames can be up to 32K bytes on the MIPS before addressing them begins to require multiple instructions, but on the SPARC the corresponding limit is 4K bytes.
The difference between the offset sizes of these machines is partially accounted for by the availability of double indexing on the SPARC, a feature that is omitted from the MIPS. How important is this omission? There are obviously cases where it is simpler to address an array if two registers can be used. In many cases, a compiler can reorganize the addressing using strength reduction to avoid the need for double indexing, another example of the MIPS design relying on more sophisticated compiler technology.
 The Instruction Set.Each instruction in the SPARC's instruction set falls into one of three formats. Since two of the formats have variants, one might say that there are actually a total of six subclasses of instruction formats. The call format is used only for procedure call instructions. The second format is used by the arithmetic and logical instructions. The SETHI format is used for one special instruction known as SETHI. The branch format is used for both conditional and unconditional branches. Fig. 5.5 shows the layout of the fields in each of these formats.
The Instruction Set.Each instruction in the SPARC's instruction set falls into one of three formats. Since two of the formats have variants, one might say that there are actually a total of six subclasses of instruction formats. The call format is used only for procedure call instructions. The second format is used by the arithmetic and logical instructions. The SETHI format is used for one special instruction known as SETHI. The branch format is used for both conditional and unconditional branches. Fig. 5.5 shows the layout of the fields in each of these formats.
All the instruction formats are 32 bits long and are distinguished by their two high-order bits. Once again, as on the MIPS, we see that the instruction formats have their fields laid out in a regular and relatively simple way. This is another instance of a RISC machine in which the need to decode instructions quickly in the pipeline has aclear effect on the instruction formats. Instructions themselves are required to be aligned on a 4-byte boundary, just as on the MIPS. As we have pointed out, this requirement simplifies the hardware, since a page fault cannot be caused by an instruction that lies across two pages, one of which has been paged out to the disk.
The General and Call Instruction Formats.The call instruction format is the simplest of the three formats with only two fields: a 2-bit opcode field and a 30-bit address field. Since all instructions are required to be aligned on a 4-byte boundary, the 30-bit address field is large enough to cover the full 32-bit logical address space (two zero bits are appended at the right end of the 30-bit address given in the instruction).
The general instruction format comes in three variants, all shown in Fig. 5.5. The first two of these formats should really be thought of as a pair, in which the interpretation of the low-order bits is controlled by bit 13, the i bit. The last of the three versions of the general format is used for the floating-point and coprocessor instructions.
The first two forms of the general format consist of a 2-bit opcode field that identifies the instruction as a general format instruction, followed by a 5-bit field specifying a destination register. This is followed by a secondary 6-bit operation field that specifies which instruction in this format is to be executed, and then a 5-bit field specifying the first of the source registers involved in the computation. The interpretation of the remaining fields of the opcode is then controlled by the bit i. If the bit i is clear, then of the remaining 13 bits in the instruction format, the low-order 5 bits specify a second source register, such as might be required in doing a register-to-register addition. Eight bits are completely ignored in this case. If the bit i is set, then the remaining 13 bits are interpreted as an immediate operand. The third general format variant is used for floating-point operations and coprocessor instructions. The first four fields are identical to those described above. Instead of the bit i controlling the interpretation of the lower-order fields, this instruction format has three fields of fixed length: a 5-bit source register field, a third opcode field 9 bits wide, and another 5-bit source register field for the second operand of a two-operand instruction.
The Load and Store Instructions.We will begin our description of the general format with the load instructions. As in most RISC processors, the load and store instructions are the only ones that can access data in memory. The assembler format for the load instructions is
ld{s,u}{b,h}{a} [rs1 + rs2], rd or ld{d}{a} [rs1 + rs2], rd
where S stands for signed, U stands for unsigned, B for byte, H for halfword, and D for doubleword. The optional character A can be appended to any one of the basic load instructions, to indicate an alternate address space access, as described below. To load a single word, for example, the instruction LD is used. To load a single byte without sign extension, LDUB is used, while to load a byte with sign extension, LDSB is used. The lead instructions specify the data type to be loaded, a byte, halfword, word, or doubleword. In the case of a byte or halfword, a programmer can specify either sign extension or zero extension to handle signed or unsigned data. The loaddoubleword instruction requires the operand to be doubleword aligned. This avoids the possibility of a page fault being caused by a single instruction. In fact, all data types must be aligned on their respective boundaries. Since the load and store instructions are the only instructions that can reference memory, it also means that the only addressing modes are those provided for this format. All the load instructions use a common format, in which rs1and rs2are used to form the effective address. The third format allows the effective address to be formed by adding rs1to rs2, i.e., double indexing but without a constant offset. The second format does allow a signed 13-bit displacement which is added to rs1, yielding an if addressing mode which allows displacements of plus or minus 4K bytes without if automatic scaling.
The store instructions are written in SPARC assembly language as
ST{B,H,D}{A} [rs1 + rs2], rd
with the optional A denoting an alternative address space just as in the case of the load instructions. This instruction allows one to store a byte, halfword, word, or doubleword into memory using either double indexing or indexing with a 13-bit signed offset. On a store, there is, of course, no issue of sign or zero extension, so we do not need multiple forms of these instructions of the sort that were required for the load instruction.
Arithmetical and Logical Instructions. Addition and Subtraction. The add instruction on the SPARC comes in several versions. In addition to the standard Add (ADD) instruction, there is an Add Extended (ADDX) instruction that can be used to extend precision by adding the carry bit from the previous addition.
Each of these instructions has another variant (written as ADDcc and ADDXcc) that gives a programmer the option of setting or not setting the condition code bits. The ability to specify which instructions affect the condition codes is quite valuable, since it is often necessary to do an addition in order to compute an address ? an operation that should not set the condition codes.
Another situation in which having this control is useful when, for example, generating code for a loop that adds 2000 numbers. As the loop executes, you may want to add the carry from one iteration of the loop to the next using the ADDX instruction. But the loop will also need an add to bump the index register. You don't want the add that bumps the index register to affect the condition codes because you will need the carry for the sum that you are computing. Having both versions of the add makes it very convenient to generate such code.
The IA addresses the same issue, although in a less general way. The INC instruction does not change the carry flag, while the ADD instruction does. The mechanism here on the SPARC is a cleaner, much more general mechanism, since all instructions for which it is relevant have the option of setting or not setting the condition codes. The subtract instructions (the assembler mnemonics being SUB and SUBX with an option cc appended) are similar to the add instructions.
Tagged Addition and Subtraction. A rather peculiar (for a RISC processor) additional set of instructions provides tagged addition and subtraction operations, where the tag is a value specified in bits 0 and 1 of each of the operands:
TADDcc
TADDccT
V TSUBcc
TSUBccTV
These instructions function in a manner similar to the corresponding ADDcc and SUBcc instructions except that the overflow bit V in the program state register is set if either of the operands has a non-zero tag or if a normal arithmetic overflow occurs. In the case of the TV variants, a trap is generated as well. In a manner reminiscent of several instructions we encountered on the CISC processors, it is natural to ask: What is the intention behind these peculiar instructions? Consider an implementation of List Processing Language (LISP), where objects are either list cells or atoms, and the atoms can be either integers or strings. The intended use of the tagged add and subtract involves using the tag of every value to indicate its type, for instance, 00 for integer, 01 for string, and 11 for pointer.
Now suppose we are generating code for the LISP expression (+ X Y), which is valid only if X and Y are integers. The tagged add instruction is just what we need. We unconditionally generate a TADDccTV instruction to add X and Y. If the LISP program is incorrect and either X or Y is not an integer, then an error trap is generated. All of this happens in a single cycle, thus eliminating the need for an explicit sequence of instructions to mask out and check the tag.
Instructions such as these are actually much more reminiscent of the sort of design we find in CISC processors. Is it really the case, even for a LISP compiler, that the frequency of use of this instruction justifies its inclusion? Although some studies suggest that the use of tagged instructions does significantly increase performance for some specialized applications, choosing to put in the tagged add and subtract in preference to many other specialized instructions is a little odd, and probably reflects some peculiar interests of the designers.
The SPARC, like some other RISC designs, does not have a full multiple-clock multiply instruction, but instead implements multiplication by executing a sequence of Multiply Step (MULScc) instructions, which do a 1-bit step of a multiplication. A 32-bit multiply takes approximately 40 clocks, including the prologue and epilogue code required to set up and complete the multiplication, as well as the 32 1-clock multiply step instructions themselves. There is a standard routine at the back of the architecture manual that shows how to implement a multiply by issuing an appropriate number of multiply step instructions.
The logical instructions include AND and AND NOT instructions (AND and ANDN), Or, and Or Not instructions (OR and ORN) as well as Exclusive OR and Exclusive OR NOT instructions. As with several other instructions, the condition codes can either be set or not set, as a programmer wishes.Using the AND instruction, you normally put a 1 in the bit mask for bits you want to keep, and 0 for bits you want to clear. In using the ANDN, things are exactly the other way around, that is, you place a 1 in the bit mask for the bits you want to clear and 0 for the bits you want to keep. There are a whole range of DEC machines that don't have the AND. Instead, they have the Bit Clear (which is the AND NOT). On the SPARC there is a full set of logical operations.
Notice that by using register 0, which you will remember, is permanently wired to 0, you can synthesize some additional operations. In particular, the one's complement or logical NOT, can be written as
R3 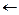 R0 ANDN R4
R0 ANDN R4
which inverts the bits in R4 and puts the result in R3. As for shift instructions, the SPARC contains the usual ones, including Shift Right Logical (SRL), Shift Left Logical (SLL), and a Shift Right Arithmetic (SRA), which is sign extended. There are no rotate instructions, and more importantly, there is no shift double instruction, which complicates the code for extracting arbitrarily positioned bit fields. One might imagine that code intended to run on RISC processors should generally avoid bit fields that can be positioned over a word boundary, but it is not always possible to avoid them.
The Conditional Branch Instructions.The Branch instruction format supports the conditional branch instructions, which include a 4-bit condition code that matches against the four standard condition code bits so that it is possible to test any combination of conditions. Two limiting cases are Never Jump and Always Jump.
Other forms of the conditional branch allow branch decisions to be based on floating-point condition codes. The interpretations of these codes are similar, although not identical, to those of the integer unit. These instructions check against a 4-bit condition code pattern. In the case of the coprocessor, a similar set of conditional branches is available, but since the interpretation of these bits is completely up to the designer of the coprocessor, no predefined meaning can be attached to them.
After all other bits have been allocated in the instruction format; 22 bits are left over for the displacement. These 22 bits really amount to 24 bits of addressing, since the address specified in the 22 bits is shifted left 2 bits by the hardware, as in the case of the call instruction format. The effect of this format is to give a signed 8-megabyte range for conditional jumps, which is certainly sufficient for most applications. One usually expects conditional jumps to occur within a single procedure, and programs are not expected to contain single procedures with more than 8 megabytes of code!
The Annul Bit. The annul bit (A-bit), which is present in all conditional jump instructions, is one of the more interesting and unusual features of the SPARC architecture. This bit makes it simpler for a compiler to fill a branch delay slot.
In many RISC machines, notably the MIPS, the instruction placed in the delay slot is executed whether or not the conditional jump is executed. This means that on such a machine the instruction that is used to fill the delay slot must be an instruction that needs to be executed regardless of whether or not the branch is taken. If such an instruction cannot be found, the delay slot must be filled with a no-op.
A useful optimization in the instruction set of the SPARC is to provide two variations for each conditional branch. If the annul bit is set and the branch is worked, then the instruction right after the branch is skipped. The processor will suppress the effects of that instruction even though it is already in the pipeline. This feature is useful because it makes it easier, for a compiler to fill the delay slot. Since the instruction in the delay slot can be annulled, there is one instruction that can always be put after the conditional branch: the instruction that is the target of the branch. For example, if the target of a branch is at location L, there must be an instruction at L. Putting that instruction into the delay slot with the annul bit set and then branching to L + 4, is a simple systematic way of filling the delay slot. On the MIPS you might not be able to find an instruction that you need in both cases and end up putting a no-op into the delay slot.
Without any specific knowledge about how the branch was being used, you might conclude that filling the delay slot with the annul bit set would be useful only half the time on average. In practice, however, the instruction in the delay slot will usually not be annulled since in the case where the conditional branch is used to control a loop, jumps are taken much more often than not. This has an interesting effect on compilers, since it means that it is very desirable to have the conditional test (that controls whether or not the loop is executed again) at the end of the loop. A while loop is naively translated by generating a test and conditional branch at the top of the loop (which controls when the loop is exited), followed by the body of the loop, and ending with an unconditional branch to the top of the loop. On any machine, performance is improved by testing the condition once on entry to the loop, and then putting the test at the bottom of the loop. This optimization is even more important on the SPARC, given the way the annul bit works.
Date: 2016-06-12; view: 724
| <== previous page | | | next page ==> |
| The SPARC Architecture | | | Floating-Point on the SPARC |