CATEGORIES:
BiologyChemistryConstructionCultureEcologyEconomyElectronicsFinanceGeographyHistoryInformaticsLawMathematicsMechanicsMedicineOtherPedagogyPhilosophyPhysicsPolicyPsychologySociologySportTourism
Nbsp; Programming Language Primitive Types
Certain data types are so commonly used that many compilers allow code to manipulate them using
simplified syntax. For example, you could allocate an integer by using the following syntax.
System.Int32 a = new System.Int32();
But I’m sure you’d agree that declaring and initializing an integer by using this syntax is rather cumbersome. Fortunately, many compilers (including C#) allow you to use syntax similar to the fol- lowing instead.
int a = 0;
This syntax certainly makes the code more readable and generates identical Intermediate Lan- guage (IL) to that which is generated when System.Int32 is used. Any data types the compiler directly supports are called primitive types. Primitive types map directly to types existing in the
Framework Class Library (FCL). For example, in C#, an int maps directly to the System.Int32 type. Because of this, the following four lines of code all compile correctly and produce exactly the same IL.
int a = 0; // Most convenient syntax
System.Int32 a = 0; // Convenient syntax int a = new int(); // Inconvenient syntax
System.Int32 a = new System.Int32(); // Most inconvenient syntax
Table 5-1 shows the FCL types that have corresponding primitives in C#. For the types that are compliant with the Common Language Specification (CLS), other languages will offer similar primitive types. However, languages aren’t required to offer any support for the non–CLS-compliant types.
TABLE 5-1C# Primitives with Corresponding FCL Types
| Primitive Type | FCL Type | CLS-Compliant | Description |
| sbyte | System.SByte | No | Signed 8-bit value |
| byte | System.Byte | Yes | Unsigned 8-bit value |
| short | System.Int16 | Yes | Signed 16-bit value |
| ushort | System.UInt16 | No | Unsigned 16-bit value |
| int | System.Int32 | Yes | Signed 32-bit value |
| uint | System.UInt32 | No | Unsigned 32-bit value |
| long | System.Int64 | Yes | Signed 64-bit value |
| ulong | System.UInt64 | No | Unsigned 64-bit value |
| char | System.Char | Yes | 16-bit Unicode character (char never represents an 8-bit value as it would in unmanaged C++.) |
| float | System.Single | Yes | IEEE 32-bit floating point value |
| double | System.Double | Yes | IEEE 64-bit floating point value |
| bool | System.Boolean | Yes | A true/false value |
| decimal | System.Decimal | Yes | A 128-bit high-precision floating-point value com- monly used for financial calculations in which round- ing errors can’t be tolerated. Of the 128 bits, 1 bit represents the sign of the value, 96 bits represent the value itself, and 8 bits represent the power of 10 to divide the 96-bit value by (can be anywhere from 0 to 28). The remaining bits are unused. |
| string | System.String | Yes | An array of characters |
| object | System.Object | Yes | Base type of all types |
| dynamic | System.Object | Yes | To the common language runtime (CLR), dynamic is identical to object. However, the C# compiler allows dynamic variables to participate in dynamic dispatch by using a simplified syntax. For more infor- mation, see “The dynamic Primitive Type” section at the end of this chapter. |
Another way to think of this is that the C# compiler automatically assumes that you have the follow- ing using directives (as discussed in Chapter 4, “Type Fundamentals”) in all of your source code files.
using sbyte = System.SByte; using byte = System.Byte; using short = System.Int16; using ushort = System.UInt16; using int = System.Int32; using uint = System.UInt32;
...
The C# language specification states, “As a matter of style, use of the keyword is favored over use of the complete system type name.” I disagree with the language specification; I prefer to use the FCL type names and completely avoid the primitive type names. In fact, I wish that compilers didn’t even offer the primitive type names and forced developers to use the FCL type names instead. Here are my reasons:
■ I’ve seen a number of developers confused, not knowing whether to use string or String in their code. Because in C# string (a keyword) maps exactly to System.String (an FCL type), there is no difference and either can be used. Similarly, I’ve heard some developers say that int represents a 32-bit integer when the application is running on a 32-bit operating system and that it represents a 64-bit integer when the application is running on a 64-bit operating system. This statement is absolutely false: in C#, an int always maps to System.Int32, and therefore it represents a 32-bit integer regardless of the operating system the code is run- ning on. If programmers would use Int32 in their code, then this potential confusion is also eliminated.
■ In C#, long maps to System.Int64, but in a different programming language, long could map to an Int16 or Int32. In fact, C++/CLI does treat long as an Int32. Someone reading source code in one language could easily misinterpret the code’s intention if he or she were used to programming in a different programming language. In fact, most languages won’t even treat long as a keyword and won’t compile code that uses it.
■ The FCL has many methods that have type names as part of their method names. For example, the BinaryReader type offers methods such as ReadBoolean, ReadInt32, ReadSingle, and so on, and the System.Convert type offers methods such as ToBoolean, ToInt32, ToSingle, and so on. Although it’s legal to write the following code, the line with float feels very un- natural to me, and it’s not obvious that the line is correct.
BinaryReader br = new BinaryReader(...);
float val = br.ReadSingle(); // OK, but feels unnatural Single val = br.ReadSingle(); // OK and feels good
■ Many programmers that use C# exclusively tend to forget that other programming languages can be used against the CLR, and because of this, C#-isms creep into the class library code. For example, Microsoft’s FCL is almost exclusively written in C# and developers on the FCL team have now introduced methods into the library such as Array’s GetLongLength, which returns an Int64 value that is a long in C# but not in other languages (like C++/CLI). Another example is System.Linq.Enumerable’s LongCount method.
For all of these reasons, I’ll use the FCL type names throughout this book.
In many programming languages, you would expect the following code to compile and execute correctly.
Int32 i = 5; // A 32bit value
Int64 l = i; // Implicit cast to a 64bit value
However, based on the casting discussion presented in Chapter 4, you wouldn’t expect this code to compile. After all, System.Int32 and System.Int64 are different types, and neither one is derived from the other. Well, you’ll be happy to know that the C# compiler does compile this code correctly, and it runs as expected. Why? The reason is that the C# compiler has intimate knowledge of primitive types and applies its own special rules when compiling the code. In other words, the compiler recog- nizes common programming patterns and produces the necessary IL to make the written code work as expected. Specifically, the C# compiler supports patterns related to casting, literals, and operators, as shown in the following examples.
First, the compiler is able to perform implicit or explicit casts between primitive types such as the following.
Int32 i = 5; // Implicit cast from Int32 to Int32 Int64 l = i; // Implicit cast from Int32 to Int64 Single s = i; // Implicit cast from Int32 to Single Byte b = (Byte) i; // Explicit cast from Int32 to Byte Int16 v = (Int16) s; // Explicit cast from Single to Int16
C# allows implicit casts if the conversion is “safe,” that is, no loss of data is possible, such as con- verting an Int32 to an Int64. But C# requires explicit casts if the conversion is potentially unsafe. For numeric types, “unsafe” means that you could lose precision or magnitude as a result of the conver- sion. For example, converting from Int32 to Byte requires an explicit cast because precision might be lost from large Int32 numbers; converting from Single to Int16 requires a cast because Single can represent numbers of a larger magnitude than Int16 can.
Be aware that different compilers can generate different code to handle these cast operations.
For example, when casting a Single with a value of 6.8 to an Int32, some compilers could generate code to put a 6 in the Int32, and others could perform the cast by rounding the result up to 7. By the way, C# always truncates the result. For the exact rules that C# follows for casting primitive types, see the “Conversions” section in the C# language specification.
In addition to casting, primitive types can be written as literals. A literal is considered to be an instance of the type itself, and therefore, you can call instance methods by using the instance as shown here.
Console.WriteLine(123.ToString() + 456.ToString()); // "123456"
Also, if you have an expression consisting of literals, the compiler is able to evaluate the expression at compile time, improving the application’s performance.
Boolean found = false; // Generated code sets found to 0 Int32 x = 100 + 20 + 3; // Generated code sets x to 123 String s = "a " + "bc"; // Generated code sets s to "a bc"
Finally, the compiler automatically knows how and in what order to interpret operators (such as +,
, *, /, %, &, ^, |, ==, !=, >, <, >=, <=, <<, >>, ~, !, ++, , and so on) when used in code.
Int32 x = 100; // Assignment operator
Int32 y = x + 23; // Addition and assignment operators Boolean lessThanFifty = (y < 50); // Lessthan and assignment operators
Checked and Unchecked Primitive Type Operations
Programmers are well aware that many arithmetic operations on primitives could result in an
overflow.
Byte b = 100;
b = (Byte) (b + 200); // b now contains 44 (or 2C in Hex).
 | |||
 | |||
In most programming scenarios, this silent overflow is undesirable and if not detected causes the application to behave in strange and unusual ways. In some rare programming scenarios (such as cal- culating a hash value or a checksum), however, this overflow is not only acceptable but is also desired.
Different languages handle overflows in different ways. C and C++ don’t consider overflows to be an error and allow the value to wrap; the application continues running. Microsoft Visual Basic, on the other hand, always considers overflows to be errors and throws an exception when it detects one.
The CLR offers IL instructions that allow the compiler to choose the desired behavior. The CLR has an instruction called add that adds two values together. The add instruction performs no overflow checking. The CLR also has an instruction called add.ovf that also adds two values together. Howev- er, add.ovf throws a System.OverflowException if an overflow occurs. In addition to these two IL instructions for the add operation, the CLR also has similar IL instructions for subtraction (sub/ sub.ovf), multiplication (mul/mul.ovf), and data conversions (conv/conv.ovf).
C# allows the programmer to decide how overflows should be handled. By default, overflow checking is turned off. This means that the compiler generates IL code by using the versions of the add, subtract, multiply, and conversion instructions that don’t include overflow checking. As a result, the code runs faster—but developers must be assured that overflows won’t occur or that their code is designed to anticipate these overflows.
One way to get the C# compiler to control overflows is to use the /checked+ compiler switch. This switch tells the compiler to generate code that has the overflow-checking versions of the add, subtract, multiply, and conversion IL instructions. The code executes a little slower because the CLR is checking these operations to determine whether an overflow occurred. If an overflow occurs, the CLR throws an OverflowException.
In addition to having overflow checking turned on or off globally, programmers can control overflow checking in specific regions of their code. C# allows this flexibility by offering checked and unchecked operators. Here’s an example that uses the unchecked operator.
UInt32 invalid = unchecked((UInt32) (1)); // OK
And here is an example that uses the checked operator.
Byte b = 100;
b = checked((Byte) (b + 200)); // OverflowException is thrown
In this example, b and 200 are first converted to 32-bit values and are then added together; the result is 300. Then 300 is converted to a Byte due to the explicit cast; this generates the Overflow Exception. If the Byte were cast outside the checked operator, the exception wouldn’t occur.
b = (Byte) checked(b + 200); // b contains 44; no OverflowException
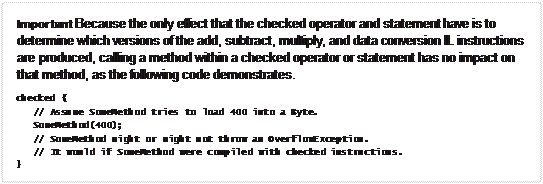
In addition to the checked and unchecked operators, C# also offers checked and unchecked
statements. The statements cause all expressions within a block to be checked or unchecked.
checked { // Start of checked block Byte b = 100;
b = (Byte) (b + 200); // This expression is checked for overflow.
} // End of checked block
In fact, if you use a checked statement block, you can now use the += operator with the Byte,
which simplifies the code a bit.
checked { // Start of checked block Byte b = 100;
b += 200; // This expression is checked for overflow.
} // End of checked block
 | |||
| | |||
In my experience, I've seen a lot of calculations produce surprising results. Typically, this is due to invalid user input, but it can also be due to values returned from parts of the system that a program- mer just doesn't expect. And so, I now recommend that programmers do the following:
■ Use signed data types (such as Int32 and Int64) instead of unsigned numeric types (such as UInt32 and UInt64) wherever possible. This allows the compiler to detect more overflow/ underflow errors. In addition, various parts of the class library (such as Array's and String's Length properties) are hard-coded to return signed values, and less casting is required as you move these values around in your code. Fewer casts make source code cleaner and easier to maintain. In addition, unsigned numeric types are not CLS-compliant.
■ As you write your code, explicitly use checked around blocks where an unwanted overflow might occur due to invalid input data, such as processing a request with data supplied from an end user or a client machine. You might want to catch OverflowException as well, so that your application can gracefully recover from these failures.
■ As you write your code, explicitly use unchecked around blocks where an overflow is OK, such
as calculating a checksum.
■ For any code that doesn’t use checked or unchecked, the assumption is that you do want an exception to occur on overflow, for example, calculating something (such as prime numbers) where the inputs are known, and overflows are bugs.
Now, as you develop your application, turn on the compiler’s /checked+ switch for debug builds. Your application will run more slowly because the system will be checking for overflows on any code that you didn’t explicitly mark as checked or unchecked. If an exception occurs, you’ll easily detect it and be able to fix the bug in your code. For the release build of your application, use the compiler’s
/checkedswitch so that the code runs faster and overflow exceptions won’t be generated. To change the Checked setting in Microsoft Visual Studio, display the properties for your project, select the Build tab, click Advanced, and then select the Check For Arithmetic Overflow/Underflow option, as shown in Figure 5-1.
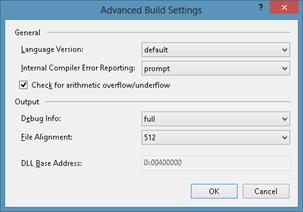 |
FIGURE 5-1Changing the compiler’s default setting for performing checked arithmetic by using Visual Studio’s Advanced Build Settings dialog box.
If your application can tolerate the slight performance hit of always doing checked operations, then I recommend that you compile with the /checked command-line option even for a release build because this can prevent your application from continuing to run with corrupted data and possible security holes. For example, you might perform a multiplication to calculate an index into an array; it is much better to get an OverflowException as opposed to accessing an incorrect array element due to the math wrapping around.

 ImportantThe System.Decimal type is a very special type. Although many programming languages (C# and Visual Basic included) consider Decimal a primitive type, the CLR does
ImportantThe System.Decimal type is a very special type. Although many programming languages (C# and Visual Basic included) consider Decimal a primitive type, the CLR does
not. This means that the CLR doesn’t have IL instructions that know how to manipulate a Decimal value. If you look up the Decimal type in the .NET Framework SDK documenta- tion, you’ll see that it has public static methods called Add, Subtract, Multiply, Divide, and so on. In addition, the Decimal type provides operator overload methods for +, , *, /, and so on.
When you compile code that uses Decimal values, the compiler generates code to call Decimal’s members to perform the actual operation. This means that manipulating Decimal values is slower than manipulating CLR primitive values. Also, because there are
no IL instructions for manipulating Decimal values, the checked and unchecked operators, statements, and compiler switches have no effect. Operations on Decimal values always throw an OverflowException if the operation can’t be performed safely.
Similarly, the System.Numerics.BigInteger type is also special in that it internally uses an array of UInt32s to represent an arbitrarily large integer whose value has no upper or lower bound. Therefore, operations on a BigInteger never result in an OverflowException.
However, a BigInteger operation may throw an OutOfMemoryException if the value gets
too large and there is insufficient available memory to resize the array.
 |
Reference Types and Value Types
The CLR supports two kinds of types: reference types and value types. Although most types in the FCL are reference types, the types that programmers use most often are value types. Reference types are always allocated from the managed heap, and the C# new operator returns the memory address of the object—the memory address refers to the object’s bits. You need to bear in mind some perfor- mance considerations when you’re working with reference types. First, consider these facts:
■ The memory must be allocated from the managed heap.
■ Each object allocated on the heap has some additional overhead members associated with it that must be initialized.
■ The other bytes in the object (for the fields) are always set to zero.
■ Allocating an object from the managed heap could force a garbage collection to occur.
If every type were a reference type, an application’s performance would suffer greatly. Imagine how poor performance would be if every time you used an Int32 value, a memory allocation oc- curred! To improve performance for simple, frequently used types, the CLR offers lightweight types called value types. Value type instances are usually allocated on a thread’s stack (although they
can also be embedded as a field in a reference type object). The variable representing the instance doesn’t contain a pointer to an instance; the variable contains the fields of the instance itself. Because the variable contains the instance’s fields, a pointer doesn’t have to be dereferenced to manipulate the instance’s fields. Value type instances don’t come under the control of the garbage collector, so their use reduces pressure in the managed heap and reduces the number of collections an application requires over its lifetime.
The .NET Framework SDK documentation clearly indicates which types are reference types and which are value types. When looking up a type in the documentation, any type called a class is a reference type. For example, the System.Exception class, the System.IO.FileStream class, and the System.Random class are all reference types. On the other hand, the documentation refers to each value type as a structure or an enumeration. For example, the System.Int32 structure, the System.Boolean structure, the System.Decimal structure, the System.TimeSpan structure, the System.DayOfWeek enumeration, the System.IO.FileAttributes enumeration, and the Sys tem.Drawing.FontStyle enumeration are all value types.
All of the structures are immediately derived from the System.ValueType abstract type.
System.ValueType is itself immediately derived from the System.Object type. By definition,
all value types must be derived from System.ValueType. All enumerations are derived from the System.Enum abstract type, which is itself derived from System.ValueType. The CLR and all pro- gramming languages give enumerations special treatment. For more information about enumer- ated types, refer to Chapter 15, “Enumerated Types and Bit Flags.”
Even though you can’t choose a base type when defining your own value type, a value type
can implement one or more interfaces if you choose. In addition, all value types are sealed, which prevents a value type from being used as a base type for any other reference type or value type. So, for example, it’s not possible to define any new types using Boolean, Char, Int32, UInt64, Single, Double, Decimal, and so on as base types.
 | |||
| | |||
The following code and Figure 5-2 demonstrate how reference types and value types differ.
// Reference type (because of 'class') class SomeRef { public Int32 x; }
// Value type (because of 'struct') struct SomeVal { public Int32 x; }
static void ValueTypeDemo() {
SomeRef r1 = new SomeRef(); // Allocated in heap SomeVal v1 = new SomeVal(); // Allocated on stack r1.x = 5; // Pointer dereference
v1.x = 5; // Changed on stack Console.WriteLine(r1.x); // Displays "5" Console.WriteLine(v1.x); // Also displays "5"
// The left side of Figure 52 reflects the situation
// after the lines above have executed.
SomeRef r2 = r1; // Copies reference (pointer) only
SomeVal v2 = v1; // Allocate on stack & copies members
r1.x = 8; // Changes r1.x and r2.x
v1.x = 9; // Changes v1.x, not v2.x Console.WriteLine(r1.x); // Displays "8" Console.WriteLine(r2.x); // Displays "8" Console.WriteLine(v1.x); // Displays "9" Console.WriteLine(v2.x); // Displays "5"
// The right side of Figure 52 reflects the situation
// after ALL of the lines above have executed.
}
In this code, the SomeVal type is declared using struct instead of the more common class.
In C#, types declared using struct are value types, and types declared using class are reference types. As you can see, the behavior of reference types and value types differs quite a bit. As you use types in your code, you must be aware of whether the type is a reference type or a value type be- cause it can greatly affect how you express your intentions in the code.
Situation after the first half of the
ValueTypeDemo method executes
Situation after the ValueTypeDemo
method completely executes
Thread Stack
Managed Heap
Thread Stack
Managed Heap


FIGURE 5-2Visualizing the memory as the code executes.
In the preceding code, you saw this line.
SomeVal v1 = new SomeVal(); // Allocated on stack
The way this line is written makes it look as if a SomeVal instance will be allocated on the managed heap. However, the C# compiler knows that SomeVal is a value type and produces code that allocates the SomeVal instance on the thread’s stack. C# also ensures that all of the fields in the value type instance are zeroed.
The preceding line could have been written like this instead.
SomeVal v1; // Allocated on stack
This line also produces IL that allocates the instance on the thread’s stack and zeroes the fields. The only difference is that C# “thinks” that the instance is initialized if you use the new operator. The fol- lowing code will make this point clear.
// These two lines compile because C# thinks that
// v1's fields have been initialized to 0. SomeVal v1 = new SomeVal();
Int32 a = v1.x;
// These two lines don't compile because C# doesn't think that
// v1's fields have been initialized to 0. SomeVal v1;
Int32 a = v1.x; // error CS0170: Use of possibly unassigned field 'x'
When designing your own types, consider carefully whether to define your types as value types instead of reference types. In some situations, value types can give better performance. In particular, you should declare a type as a value type if all the following statements are true:
■ The type acts as a primitive type. Specifically, this means that it is a fairly simple type that has no members that modify any of its instance fields. When a type offers no members that alter its fields, we say that the type is immutable. In fact, it is recommended that many value types mark all their fields as readonly (discussed in Chapter 7, "Constants and Fields").
■ The type doesn’t need to inherit from any other type.
■ The type won’t have any other types derived from it.
The size of instances of your type is also a condition to take into account because by default, arguments are passed by value, which causes the fields in value type instances to be copied, hurt- ing performance. Again, a method that returns a value type causes the fields in the instance to be
copied into the memory allocated by the caller when the method returns, hurting performance. So, in addition to the previous conditions, you should declare a type as a value type if one of the following statements is true:
■ Instances of the type are small (approximately 16 bytes or less).
■ Instances of the type are large (greater than 16 bytes) and are not passed as method param- eters or returned from methods.
The main advantage of value types is that they’re not allocated as objects in the managed heap. Of course, value types have several limitations of their own when compared to reference types. Here are some of the ways in which value types and reference types differ:
■ Value type objects have two representations: an unboxed form and a boxed form (discussed in the next section). Reference types are always in a boxed form.
■ Value types are derived from System.ValueType. This type offers the same methods as defined by System.Object. However, System.ValueType overrides the Equals method so that it returns true if the values of the two objects’ fields match. In addition, System.Value Type overrides the GetHashCode method to produce a hash code value by using an algorithm that takes into account the values in the object’s instance fields. Due to performance issues with this default implementation, when defining your own value types, you should override and provide explicit implementations for the Equals and GetHashCode methods. I’ll cover the Equals and GetHashCode methods at the end of this chapter.
■ Because you can’t define a new value type or a new reference type by using a value type as a base class, you shouldn’t introduce any new virtual methods into a value type. No methods can be abstract, and all methods are implicitly sealed (can’t be overridden).
■ Reference type variables contain the memory address of objects in the heap. By default, when a reference type variable is created, it is initialized to null, indicating that the reference type variable doesn’t currently point to a valid object. Attempting to use a null reference type variable causes a NullReferenceException to be thrown. By contrast, value type variables always contain a value of the underlying type, and all members of the value type are initial- ized to 0. Because a value type variable isn’t a pointer, it’s not possible to generate a Null ReferenceException when accessing a value type. The CLR does offer a special feature that adds the notion of nullability to a value type. This feature, called nullable types, is discussed in Chapter 19, “Nullable Value Types.”
■ When you assign a value type variable to another value type variable, a field-by-field copy is made. When you assign a reference type variable to another reference type variable, only the memory address is copied.
■ Because of the previous point, two or more reference type variables can refer to a single object in the heap, allowing operations on one variable to affect the object referenced by the other variable. On the other hand, value type variables are distinct objects, and it’s not possible for operations on one value type variable to affect another.
■ Because unboxed value types aren’t allocated on the heap, the storage allocated for them is freed as soon as the method that defines an instance of the type is no longer active as op- posed to waiting for a garbage collection.
 How the CLR Controls the Layout of a Type’s Fields
How the CLR Controls the Layout of a Type’s Fields
To improve performance, the CLR is capable of arranging the fields of a type any way it chooses. For example, the CLR might reorder fields in memory so that object references are grouped together and data fields are properly aligned and packed. However, when you define a type, you can tell the CLR whether it must keep the type’s fields in the same order as the developer specified them or whether it can reorder them as it sees fit.
You tell the CLR what to do by applying the System.Runtime.InteropServices.Struct LayoutAttribute attribute on the class or structure you’re defining. To this attribute’s constructor, you can pass LayoutKind.Auto to have the CLR arrange the fields, Layout
Kind.Sequential to have the CLR preserve your field layout, or LayoutKind.Explicit
to explicitly arrange the fields in memory by using offsets. If you don’t explicitly specify the StructLayoutAttribute on a type that you’re defining, your compiler selects whatever lay- out it determines is best.
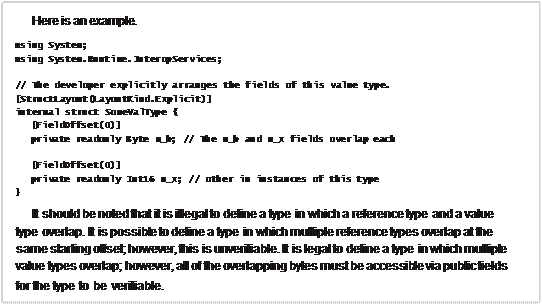
You should be aware that Microsoft’s C# compiler selects LayoutKind.Auto for reference types (classes) and LayoutKind.Sequential for value types (structures). It is obvious that the C# compiler team believes that structures are commonly used when interoperating with un- managed code, and for this to work, the fields must stay in the order defined by the program- mer. However, if you’re creating a value type that has nothing to do with interoperability with unmanaged code, you could override the C# compiler’s default. Here’s an example.
using System;
using System.Runtime.InteropServices;
// Let the CLR arrange the fields to improve
// performance for this value type. [StructLayout(LayoutKind.Auto)] internal struct SomeValType {
private readonly Byte m_b; private readonly Int16 m_x;
...
}
The StructLayoutAttribute also allows you to explicitly indicate the offset of each field by passing LayoutKind.Explicit to its constructor. Then you apply an instance of the System.Runtime.InteropServices.FieldOffsetAttribute attribute to each field passing to this attribute’s constructor an Int32 indicating the offset (in bytes) of the field’s first byte from the beginning of the instance. Explicit layout is typically used to simulate what would be a union in unmanaged C/C++ because you can have multiple fields starting at the same offset in memory.
Date: 2016-03-03; view: 905
| <== previous page | | | next page ==> |
| Nbsp; How Things Relate at Run Time | | | Nbsp; Boxing and Unboxing Value Types |