CATEGORIES:
BiologyChemistryConstructionCultureEcologyEconomyElectronicsFinanceGeographyHistoryInformaticsLawMathematicsMechanicsMedicineOtherPedagogyPhilosophyPhysicsPolicyPsychologySociologySportTourism
Comparison of Triclustering Methods
National Research University Higher School of Economics
Faculty of Business Informatics
School of Applied Mathematics and Information Science
Department of Data Analysis and Artificial Intelligence
DRAFT
of the paper
«Comparative Study of Triclustering Methods and their Applications»
Student: Dmitry Gnatyshak
Group: 471ПМИ
Argument Consultant: Dmitry I. Ignatov
Style and Language Consultant: Elena A. Golubovskaya
Abstract. Modern world is filled with an enormous amount of various data, most of which is unstructured. Clustering methods are used to reveal some hidden dependencies and thus to gather some new information. Triclustering methods aim at finding dense structures consisting of 3 sets: objects, attributes and conditions. In this paper a few of such methods are tested, namely: OAC-Triclustering, TBox, Trias and Spectral Triclustering. Moreover some alternative methods, like pseudo-triclustering, are proposed. The latter is suggested to be used in situations where there is no information about relations between attributes and conditions in order to predict some correspondence between them. Finally some suggestions on the use of these algorithms are given depending on results of comparison.
Contents
Introduction. 4
Triclustering. 6
Comparison of Triclustering Methods. 10
Pseudo Triclustering. 11
Results. 12
Conclusion. 13
Bibliography. 14
Introduction
The necessity to structure and mine information from huge amount of data is one of the major problems of modern Data Analysis and Computer Science. A lot of potentially beneficial knowledge can be extracted from different sets of sources. Clustering is a significant group of methods that can reveal hidden inner structure of data, dividing it into more or less homogenous groups. Biclustering and triclustering are subgroups of these methods aimed at finding clusters simultaneously for respective sets of objects and attributes and sets of objects, attributes and conditions. The possible range of its applications includes social networks analysis, mining resource-sharing systems, knowledge discovery from various reports, etc.
The principal goal of this paper is to compare different modern approaches to the problem of triclustering and to make some recommendations based on the results. Also an alternative method is proposed. It was called pseudo-triclustering due to its nature of being only a resemblance of original triclustering models. The main hypothesis to prove here is that the pseudo-triclustering can really be used to predict new interdependencies in the collection of data. Putting it differently, it should be clearly displayed that the corresponding assumptions and the method itself are valid.
In order to reach these goals following data collections were used for testing: database of some of Vkontakte.ru users, primarily their interests and groups; database of bybsonomy.org, the resource for sharing bookmarks and lists of literature.
Most of the used methods are purely numeric. Depending on the values of parameters its output can vary making them on the other hand more versatile. Also these methods can be labeled as data analysis methods, for they are used to reveal some new information out of data. Principal methods of triclustering used in this work are OAC-triclustering, TBox, Trias (in fact, it is a method for finding triclusters as triconcepts) and Spectral triclustering.
Some related papers are used as a background for this paper. They contain description of various biclustering and triclustering methods as well as some formal concept analysis theory needed.
The main part of the paper is divided into 4 parts. The first one gives the description of triclustering and focuses on OAC-triclustering method as well as on its main issues. Some of them include:
1) High computational complexity. Given the frame of the cluster, it costs much to compute its density. Thus the problem of finding adequate estimates arises: while it is relatively easy to find lower-bound estimate, it is much more difficult to find upper-bound estimate.
2) Halt criterion, i.e. defining when to stop searching for new triclusters. In huge formal contexts it can be quite expensive to search for all possible triclusters. Thus, there exist some approaches to determine when to stop. One of them, for instance, is to stop when a certain percentage of the context is covered by triclusters.
3) Duplicates. The same bi- or tricluster can be generated by different pairs or triples. Therefore we have to eliminate these duplicates, but checking if a current cluster is already included into the previously generated set is a very expensive operation. Some alternative approaches are considered, such as comparing the hash-values of clusters, instead of full comparison.
In the second part different triclustering methods are compared. All of them were named previously and consist of OAC-triclustering, TBox, Trias and Spectral triclustering.
In the third part an alternative method of triclustering – the pseudo-triclustering is proposed. It aims at the analysis of two formal contexts with the same extent by means of creating tricluster-like structures of their bicluster sets.
And in the fourth part all of the results are summed up.
Triclustering
Triclustering is a powerful tool for working with related sets of data in the field of Formal Concept Analysis (FCA). Thus, before elaborating on triclustering methods, some essential information about formal concept analysis and basic definitions should be given.
Cartesian product of two sets A and B is the set of ordered pairs the first element of which is a member of A and the second – of B [1]. Thus, this statement can be rewritten as:
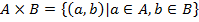
Now it is possible to define binary relation, one of the key concepts used by FCA: Binary relation R over sets A and B is the subset of Cartesian product of these two sets [1]:

Usually the fact that the ordered pair  belongs to the relation R is denoted as follows:
belongs to the relation R is denoted as follows:
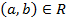 ,
,
but there are also some other popular alternative ways of notation, such as infix notation:
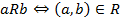
The concept of binary relation is widely used in various areas of mathematics and related fields of study, such as mathematical logic, graph theory, algebra, etc.
The important property of binary relation is that it can be represented as a matrix: let rows of matrix M represent elements of set A, columns – elements of B (thus, the dimensionality of the matrix is  , where
, where  denote the number of elements in corresponding set). Element
denote the number of elements in corresponding set). Element  of M then is equal to 1 if the pair
of M then is equal to 1 if the pair 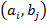 is a member of R and 0 otherwise:
is a member of R and 0 otherwise:

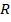
| 
| 
|
|
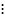
|
| ||
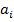
|
|
| |
|
|
While speaking of relations it would be also helpful to generalize this definition on the n-ary case. Although it is not needed for the general statement of formal concept analysis principles, it will be helpful for the following definition of triclusters. First of all, Cartesian product definition must be generalized: Cartesian product of sets  is the set of ordered sets in which ith element is a member of
is the set of ordered sets in which ith element is a member of  :
:

Then, the n-ary relation R over sets is the subset of Cartesian product of these sets:
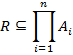
Now it is possible to describe the main principles of formal concept analysis (more thorough description can be found in “Formal Concept Analysis: Mathematical Foundations”[2]).
First of all, let  and
and 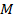 be some sets. Let
be some sets. Let 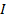 be a binary relation over and :
be a binary relation over and : 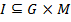 . Then the triple
. Then the triple 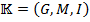 is called formal context.
is called formal context.
This structure can be easily interpreted: is a set of objects (from German Gegenstände - objects), M is a set of attributes (Merkmale),  the object g possesses the attribute m.
the object g possesses the attribute m.
The next important concept is Galois connection that is defined as follows: assume following maps:  and
and  (
( 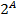 denotes the set of all subsets of A).
denotes the set of all subsets of A).
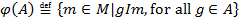
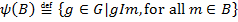
 and
and 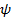 are considered to define Galois connection between
are considered to define Galois connection between 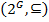 and
and  .
.
Operators and are vital for FCA as they are used to build formal concepts and biclusters. Usually they both are denoted by the derivation (prime) operator “  “, as it is clear which one of the sets it is applied to.
“, as it is clear which one of the sets it is applied to.
But the main aim of FCA is extracting so called formal concepts and analyzing them. Given the formal context in the matrix form (i.e. the matrix form of ) formal concepts can be described by maximal rectangles full of “ones”. They represent some dependencies over the attributes shared by some group of objects, thus revealing some hidden structure of a certain input data set. Mathematically formal concepts can be found using the prime operator: the pair 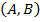 is called formal concept if
is called formal concept if 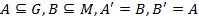 [2].
[2]. 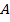 is also called extent of the formal concept,
is also called extent of the formal concept,  – intent.
– intent.
Formal concepts are very useful in the task of finding hidden structure, but they are rather rigid. It is good for definite formal contexts all data of which is known and contains no missing values and no errors. But it is highly unlikely to get such real-world dataset. Biclusters are used as a way to avoid this problem by admitting some zeroes inside “concepts”.
First of all the concept of cluster in formal concept analysis should be defined. Basically, clusters are the groups of objects, united by their similarity. Thus, in FCA two types of clusters are possible: object clusters and attribute clusters. Object clusters can be described as the groups of similar rows and attribute clusters as groups of similar columns.
Biclusters are the next step of this logic. Following definition uses Concept-based approach and is described in “A Concept-based Biclustering Algorithm”[3]. Just like formal concepts, biclusters consist of two sets: 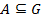 and
and 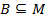 ; but unlike formal concepts they do not have to have “ones” in each cell of the corresponding matrix. The minimal ratio of “ones” to the number of cells defines whether some rectangle is admissible or not. In order to define biclusters mathematically two more definitions are needed: object concept of the formal context is the pair
; but unlike formal concepts they do not have to have “ones” in each cell of the corresponding matrix. The minimal ratio of “ones” to the number of cells defines whether some rectangle is admissible or not. In order to define biclusters mathematically two more definitions are needed: object concept of the formal context is the pair  . Attribute concept is the pair
. Attribute concept is the pair 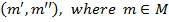 . Let
. Let  be the set of all object concepts and
be the set of all object concepts and  be the set of all attribute concepts.
be the set of all attribute concepts.
Then for the formal context and any pair of object and attribute concepts 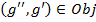 and
and 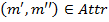 for which
for which  (or equivalently
(or equivalently  ) the pair
) the pair 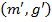 is called bicluster.
is called bicluster.
It is clear that in the matrix form biclusters look like a cross of “ones”, surrounded by some other values. As it was mentioned previously, the ratio of “ones” to the number of cells defines the quality of the bicluster. This measure is called density and will be defined further.
For the formal context and the bicluster ,  , the measure
, the measure  is called density of bicluster . Obviously, values of
is called density of bicluster . Obviously, values of 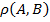 vary between 0 and 1 inclusive. And it is also clear, that for formal concepts
vary between 0 and 1 inclusive. And it is also clear, that for formal concepts 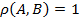 .
.
And finally, further generalization leads to the concept of triclusters described in “From Triconcepts to Triclusters” [4].
Let  (alternatively,
(alternatively, 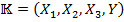 ) denote a triadic context. and are the same as in dyadic formal context, stands for the conditions set (Bedingungen),
) denote a triadic context. and are the same as in dyadic formal context, stands for the conditions set (Bedingungen), 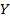 is the ternary relation
is the ternary relation  . Notation
. Notation  means that object
means that object 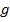 possesses attribute
possesses attribute  under condition
under condition 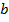 . Therefore, triadic formal contexts can be represented as three-dimensional matrices.
. Therefore, triadic formal contexts can be represented as three-dimensional matrices.
Formal triconcepts and triclusters are also defined in the similar way as in the dyadic case. As dyadic formal concepts can be described as maximal rectangles of “ones” in 2D-case, triadic formal concepts can be described as a maximal cuboid in the corresponding 3D matrix of relation . For the strict definition, following statements must firstly be made: the triadic formal context gives rise to the following dyadic formal context: 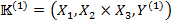 ,
,  , and
, and  , for which
, for which 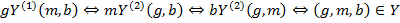 [4]. In this case the prime operator for the context
[4]. In this case the prime operator for the context 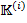 is denoted as
is denoted as 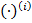 . As in dyadic case there are two such operators for each dyadic context, but in this situation one maps from
. As in dyadic case there are two such operators for each dyadic context, but in this situation one maps from  to
to  , and the other – from to ,
, and the other – from to ,  . Then the triadic formal concept of the triadic formal context is the triple
. Then the triadic formal concept of the triadic formal context is the triple  in which
in which 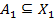 ,
, 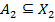 , and
, and  , and for any for which
, and for any for which 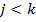 the statement
the statement  is true [4]. Its components are called respectively extent, intent and modus.
is true [4]. Its components are called respectively extent, intent and modus.
There are several approaches to the definition of triclusters. One of them is OAC-clustering (Object-Attribute-Condition). These approach shares the same features as the Concept-based approach to definition of biclusters. To formally define triclusters element-base prime and box operators must be defined. The prime operators [4 : 259]:
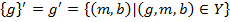

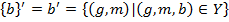
Instead of the double prime operators box operators are used [4 : 259]:

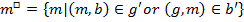
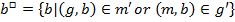
Then for the triadic formal context for the triple let tricluster be the triple  [4 : 259].
[4 : 259].
As in the previous case the concept of density of the tricluster is vital. It is defined as the ration of all triples in the triclusters to all the triples [4 : 259]:

It as well varies from 0 to 1 inclusive and for triadic formal concepts equals to 1.
Although triclusters are very useful for revealing hidden structure of triadic datasets, it is difficult to analytically compute them given the minimal admissible density. The computational complexity of the process of finding all possible triclusters is exceptionally high: given the triple 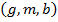 prime and box operators should be applied to all of its components. Complexities for the prime operators in the worst case are respectively
prime and box operators should be applied to all of its components. Complexities for the prime operators in the worst case are respectively  ,
,  , and
, and 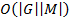 , for all the pairs must be enumerated. For the box operator all pairs in corresponding prime sets must be enumerated. That gives following complexities:
, for all the pairs must be enumerated. For the box operator all pairs in corresponding prime sets must be enumerated. That gives following complexities:  ,
, 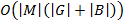 , and
, and 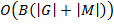 . Therefore, final computational complexity for each triple is
. Therefore, final computational complexity for each triple is  . These operations must be done over all of the triples of . In worst case there are
. These operations must be done over all of the triples of . In worst case there are 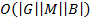 such triples. And finally, for each tricluster found this way density must be calculated that also has complexity of in the worst case. It is clear that for huge real-world data such computations are too expensive in computational resources. Thus, there are several approaches to uplift it.
such triples. And finally, for each tricluster found this way density must be calculated that also has complexity of in the worst case. It is clear that for huge real-world data such computations are too expensive in computational resources. Thus, there are several approaches to uplift it.
First of the two approaches considered in this paper is to replace computationally-expensive density by some heuristic. For instance, only some proportion of the triples of tricluster can be calculated, or even some constant number. The first variant has the same complexity as the normal variant, but in practice, it can several times decrease the time of computations.
Also some function of lower and upper boundaries of density can be used as heuristic. Possible lower boundary is trivial – the number of “ones” in generating planes formed by prime operators. But the main issue is finding the possible variant for the upper boundary. This problem currently is worked out.
The main idea of the second approach is that it is not always vital to find all possible triclusters. Here several approaches are also possible. One variant is to use the concept of the coverage of the context. Each formed tricluster covers some portion of the context. The idea is to stop the computations when these triclusters cover some fixed percentage of it. Greedy approach is also possible. The matrix of the context can be arranged in the special order so that the most number of “ones” were concentrated in one of its angles. Then it is possible to choose such a configuration of cuboids that gives some good coverage percentage.
And finally by the provided algorithm several instances of the same tricluster can be received. It is computationally expensive to compare all of the elements of the new tricluster to the elements of all other triclusters found. The possible solution is once again to use some heuristic that will represent tricluster for the purpose of comparison. In this paper hash-based approach is suggested. Its main idea is to assign each tricluster some numeric value based on the values of its elements. As for all hash functions values received in this manner must evenly cover the whole range of its possible values and even for very similar objects they must significantly differ. By this approach the complexity of the comparison of triclusters turns to  . Therefore by accepting the extremely low probability of loss of some triclusters (that is per se possible only in huge datasets) it is possible to avoid the problem of duplicates.
. Therefore by accepting the extremely low probability of loss of some triclusters (that is per se possible only in huge datasets) it is possible to avoid the problem of duplicates.
Comparison of Triclustering Methods
In the previous part of the paper OAC-clustering method was considered, as it is the main method for this work. In the following part three more methods will be mentioned and some prediction on the results of their comparison will be made.
The first of these methods is TBox described in [6]. It uses optimization approach to find the sets of triclusters that have maximal contributions to the triadic context. The main idea is to start with some triple and then expand it in the way, so that it covers the most area of the cuboid and simultaneously maintains high number of “ones” within it. There is also the similar method for finding biclusters – the BBox, and it can also be generalized to the p-ary case. The significant drawback of this approach despite its exceptional quality is its high computational complexity. Authors of the “Approximate Bicluster and Tricluster Boxes in the Analysis of Binary Data” [6] suggested applying main part of the algorithm only to instances that were not yet included in any cluster to ease the complexity, but it is still the main issue of the method.
The second triclustering method is spectral clustering in triadic case. Its main idea is to represent triadic formal concept in (2D) matrix form and then by means of finding eigenvalues and eigenvectors to divide the context into smaller parts. This process is repeated recursively until there is only one component in one of the sets of the received tricluster. Then appropriate division is chosen, either automatically by some preset conditions or manually. Again, the downside of this method is that it is analytical, thus making it very computationally expensive. But it is possible to use numeric approach for the inner calculations in order to make it more efficient on large real-world datasets.
The last algorithm in this part is Trias, described in [5]. It stands out of the other methods, for it is aimed at finding triconcepts, but they can be interpreted as absolutely dense triclusters and it will be useful to compare this algorithm to the others. Trias finds triconcepts with extent, intent and modus having the number of elements bigger than some predefined value. It works by enumerating dyadic formal concepts in dyadic contexts until they form a maximal cuboid of “ones”, i.e. formal triconcepts.
As it is expected TBox and spectral clustering should take more time to complete but they will provide triclusters of better quality. Trias will only find triconcepts, thus outputting smaller number of triples that nevertheless will be easy to interpret. OAC-clustering is likely to provide the maximal number of triclusters of various densities for moderate time.
Date: 2015-12-24; view: 671
| <== previous page | | | next page ==> |
| Szlig;³ñÅÁÝóóÁ 2006-2013 4 page | | | Pseudo-Triclustering |