CATEGORIES:
BiologyChemistryConstructionCultureEcologyEconomyElectronicsFinanceGeographyHistoryInformaticsLawMathematicsMechanicsMedicineOtherPedagogyPhilosophyPhysicsPolicyPsychologySociologySportTourism
ARTIFICIAL NEURAL NETWORKS
ARTIFICIAL NEURAL NETWORKS
Olexander Voznyuk
National Aviation University
Abstract
In modern software implementations of artificial neural networks, the approach inspired by biology has been largely abandoned for a more practical approach based on statistics and signal processing. In some of these systems, neural networks or parts of neural networks form components in larger systems that combine both adaptive and non-adaptive elements. Historically, the use of neural networks models marked a paradigm shift in the late eighties from high-level artificial intelligence, characterized by expert systems with knowledge embodied in if-then rules, to low-level machine learning, characterized by knowledge embodied in the parameters of a dynamical system.
ARTIFICIAL NEURAL NETWORKS
An Artificial Neural Network (ANN) is an information processing paradigm that is inspired by the way biological nervous systems, such as the brain, process information. The key element of this paradigm is the novel structure of the information processing system. It is composed of a large number of highly interconnected processing elements (neurons) working in unison to solve specific problems. ANNs, like people, learn by example. An ANN is configured for a specific application, such as pattern recognition or data classification, through a learning process. Learning in biological systems involves adjustments to the synaptic connections that exist between the neurons. This is true of ANNs as well.
The word network in the term 'artificial neural network' refers to the inter–connections between the neurons in the different layers of each system. An example system has three layers. The first layer has input neurons which send data via synapses to the second layer of neurons, and then via more synapses to the third layer of output neurons. More complex systems will have more layers of neurons with some having increased layers of input neurons and output neurons. The synapses store parameters called "weights" that manipulate the data in the calculations.
Introduction
Neural networks, with their remarkable ability to derive meaning from complicated or imprecise data, can be used to extract patterns and detect trends that are too complex to be noticed by either humans or other computer techniques. A trained neural network can be thought of as an "expert" in the category of information it has been given to analyse. This expert can then be used to provide projections given new situations of interest and answer "what if" questions.
Other advantages include:
- Adaptive learning: An ability to learn how to do tasks based on the data given for training or initial experience.
- Self-Organization: An ANN can create its own organization or representation of the information it receives during learning time.
- Real Time Operation: ANN computations may be carried out in parallel, and special hardware devices are being designed and manufactured which take advantage of this capability.
- Fault Tolerance via Redundant Information Coding: Partial destruction of a network leads to the corresponding degradation of performance. However, some network capabilities may be retained even with major network damage.
An ANN is typically defined by three types of parameters:
1. The interconnection pattern between the different layers of neurons
2. The learning process for updating the weights of the interconnections
3. The activation function that converts a neuron's weighted input to its output activation.
Mathematically, a neuron's network function  is defined as a composition of other functions
is defined as a composition of other functions 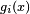 , which can further be defined as a composition of other functions. This can be conveniently represented as a network structure, with arrows depicting the dependencies between variables. A widely used type of composition is the nonlinear weighted sum, where
, which can further be defined as a composition of other functions. This can be conveniently represented as a network structure, with arrows depicting the dependencies between variables. A widely used type of composition is the nonlinear weighted sum, where 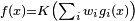 , where
, where 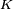 (commonly referred to as the activation function) is some predefined function, such as the hyperbolic tangent. It will be convenient for the following to refer to a collection of functions
(commonly referred to as the activation function) is some predefined function, such as the hyperbolic tangent. It will be convenient for the following to refer to a collection of functions 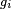 as simply a vector
as simply a vector 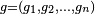 .
.
This figure depicts such a decomposition of  , with dependencies between variables indicated by arrows. These can be interpreted in two ways.
, with dependencies between variables indicated by arrows. These can be interpreted in two ways.
The first view is the functional view: the input  is transformed into a 3-dimensional vector
is transformed into a 3-dimensional vector  , which is then transformed into a 2-dimensional vector
, which is then transformed into a 2-dimensional vector  , which is finally transformed into . This view is most commonly encountered in the context of optimization.
, which is finally transformed into . This view is most commonly encountered in the context of optimization.
The second view is the probabilistic view: the random variable 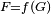 depends upon the random variable
depends upon the random variable 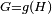 , which depends upon
, which depends upon 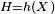 , which depends upon the random variable
, which depends upon the random variable 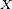 . This view is most commonly encountered in the context of graphical models.
. This view is most commonly encountered in the context of graphical models.
The two views are largely equivalent. In either case, for this particular network architecture, the components of individual layers are independent of each other (e.g., the components of are independent of each other given their input ). This naturally enables a degree of parallelism in the implementation.
Artificial Learning
What has attracted the most interest in neural networks is the possibility of learning. Given a specific task to solve, and a class of functions 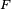 , learning means using a set of observations to find
, learning means using a set of observations to find 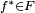 which solves the task in some optimal sense.
which solves the task in some optimal sense.
This entails defining a cost function 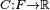 such that, for the optimal solution
such that, for the optimal solution 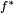 ,
, 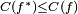
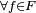 – i.e., no solution has a cost less than the cost of the optimal solution (see Mathematical optimization).
– i.e., no solution has a cost less than the cost of the optimal solution (see Mathematical optimization).
The cost function 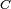 is an important concept in learning, as it is a measure of how far away a particular solution is from an optimal solution to the problem to be solved. Learning algorithms search through the solution space to find a function that has the smallest possible cost.
is an important concept in learning, as it is a measure of how far away a particular solution is from an optimal solution to the problem to be solved. Learning algorithms search through the solution space to find a function that has the smallest possible cost.
For applications where the solution is dependent on some data, the cost must necessarily be a function of the observations; otherwise we would not be modeling anything related to the data. It is frequently defined as a statistic to which only approximations can be made. As a simple example, consider the problem of finding the model , which minimizes 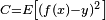 , for data pairs
, for data pairs 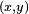 drawn from some distribution
drawn from some distribution 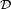 . In practical situations we would only have
. In practical situations we would only have 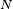 samples from and thus, for the above example, we would only minimize
samples from and thus, for the above example, we would only minimize 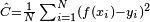 . Thus, the cost is minimized over a sample of the data rather than the entire data set.
. Thus, the cost is minimized over a sample of the data rather than the entire data set.
When 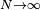 some form of online machine learning must be used, where the cost is partially minimized as each new example is seen. While online machine learning is often used when is fixed, it is most useful in the case where the distribution changes slowly over time. In neural network methods, some form of online machine learning is frequently used for finite datasets.
some form of online machine learning must be used, where the cost is partially minimized as each new example is seen. While online machine learning is often used when is fixed, it is most useful in the case where the distribution changes slowly over time. In neural network methods, some form of online machine learning is frequently used for finite datasets.
Learning paradigms
There are three major learning paradigms, each corresponding to a particular abstract learning task. These are supervised learning, unsupervised learning and reinforcement learning.
Date: 2015-12-18; view: 888
| <== previous page | | | next page ==> |
| Details about Organizers | | | Supervised learning |